
Gravwell Query Specification#
Introduction#
This is the reference specification the Gravwell query language syntax. A query is made up of indexer and webserver constraints, modules, a pipeline, and a renderer. This document provides documentation for how input text is interpreted and tokenized. Some lexical meaning of input is also defined here. Modules have context-specific semantics that differ between modules (such as numbers being implied to be strings). The user should read the search module documentation for more information on module-specific considerations.
Text Encoding#
All Gravwell input is Unicode text encoded in UTF-8.
Characters and digits#
A “character” is any of the Unicode points in the “General Category” of the Unicode specification, (The Unicode Standard 8.0, Section 4.5). This includes letters, numbers, marks, symbols, and punctuation.
Lexical grammar#
This section defines the syntax of a Gravwell query. Token semantics are module-specific, so the user should read the search module documentation for more information on module-specific considerations.
Note
The grammar is specified using pbpg, which is similar to Extended Backus–Naur form. pbpg is itself specified with pbpg and contains the following rules:
Production = Name "=" [ Expression ] "."
Expression = Alternative { "|" Alternative } .
Alternative = Term { Term } .
Term = Lex | Name | Literal | Group | Option | Repetition .
Group = "(" Expression ")" .
Option = "[" Expression "]" .
Repetition = "{" Expression "}" .
Lex = "lex" "(" LexFunction ")" .
Literal = "\"" String "\"" .
Quotes#
Many characters and keywords have special meaning in the Gravwell syntax. When using a special character or keyword as a literal string, you must use double quoted strings ". For example
json foo bar | table
extracts foo and bar from some JSON input, then passes the extractions to the table renderer. To use whitespace and the | character, both of which have special meaning, in the input to the json module, use a quoted string:
{
"TS":"2022-05-06T09:48:41.371259747-06:00",
"foo bar | table":"data!"
}
json "foo bar | table"
This example will extract a field named foo bar | table from the above JSON.
All other lexical definitions below are implied to be interpreted outside of a quoted string, except for escaped productions, which are always interpreted.
A quoted string is defined as
quoted_string = '"' { unicode_print | whitespace } '"'
whitespace = Characters from Unicode's whitespace category and Unicode category Z
unicode_print = Characters from Unicode categories L, M, N, P, and S
Escaped input#
Escaped text follows the same rules as described in the Rune Literals section of the Go programming language specification. See that document for more information.
Whitespace#
Whitespace is defined as all Unicode whitespace characters, which includes whitespace characters outside of the Latin-1 category. Whitespace characters are folded, meaning multiple, continuous whitespace characters are interpreted as a single whitespace character. Whitespace delimits tokens when used outside of a quoted string.
For example, the input
json foo bar
is made up of three tokens json, foo, and bar. In the json module in Gravwell, this would extract two enumerated values foo and bar.
Quoted whitespace is treated as part of a single string. For example, the input
json "foo bar"
is made up of two tokens json, and foo bar. The json module in this case would extract a single enumerated value named foo bar.
Whitespace is defined as
whitespace = Characters from Unicode's whitespace category and Unicode category Z
Module tokens#
Tokens are groups of characters separated by whitespace (as defined above) and reserved characters (such as |), unless grouped in a quoted string. The semantic meaning of a token depends on the position the token occurs in the input. For example,
tag=default json tag
extracts the enumerated value tag, using the json module, all from the default Gravwell tag. While the token tag shows up twice, the meaning is different based on the position in the input. The first occurrence tells Gravwell to pull data from the default tag. The second occurrence tells the json module to extract a value named tag.
Tokens cannot contain the following reserved characters, unless quoted:
Character |
Description |
|---|---|
| |
Pipe: separates modules in the module pipeline |
@ |
Compound query reference |
{} |
Compound query block |
; |
Compound query delimiter |
= |
Assignment operator |
==, <, >, <=, >=, ~, !=, !~ |
Comparison operators |
., !, #, $, %, ^, &, *, (, ), [, ], ? |
Other reserved characters |
Tokenizing in the R-value of a filter#
When filtering, tokenizing in the R-value (the value of the filter) of the filter behaves differently. All reserved characters except |[](){} will be considered part of the token until the next whitespace character. This means that while uint16(Data[2:5]) is split into 9 tokens (all reserved characters cause token splitting), the filter value in foo == ::!!!.50 is a single token.
Tokenizing in eval and code fragments#
Gravwell syntax supports inline code fragments for filtering and other operations. This is accomplished with either the eval module, followed by the code fragment, or a module stage wrapped in parentheses. For example,
tag=default json foo-bar baz | eval baz > 10 | table
has the code fragment baz > 10. This is easily parsed using the tokenizing rules described above. This same query can be written as
tag=default json foo-bar baz | (baz>10) | table
However, the code fragment syntax supports C-style notation for bitwise and logic operations, so Gravwell parses these fragments differently than the regular token stream. For example,
tag=default json foo-bar foo bar | ( foo-bar > 10 ) | table
has a code fragment foo-bar > 10, but it is unclear if the user meant “foo minus bar is greater than 10” or “the enumerated value ‘foo-bar’ is greater than 10”. This is because hyphens are allowed in the tokenizing in the json module preceding the code fragment.
Another example,
tag=default json foo bar | ( baz = foo | bar ) | table
has an interior | character, which would otherwise cause a module split, but the intended use here is to perform a bitwise-or of the two enumerated values “foo” and “bar”.
To reconcile this behavior, eval and implied code fragments tokenize in a different way:
Enumerated value names (identifiers in the grammar below) are limited to unquoted strings beginning with a non-number, and not containing any of the special characters in the grammar below.
String literals must be quoted.
Numeric literals are all forms of numbers, floating point numbers, hexadecimal syntax (eg 0xfa), and binary (eg 0b0010).
|and||are treated as bitwise and logical OR operations, respectively.
Note
Enumerated values containing reserved characters or whitespace cannot be used in code fragments. These variables must be renamed or aliased.
This form of tokenizing occurs until the outermost parenthetical group in the code fragment is closed.
Operators and filters#
Operators are reserved characters that are used when applying filters in certain modules. Filters, and their operators, are always in the form of
<identifier> <operator> <value>
For example,
foo <= 1.5
applies a filter on the identifier foo, requiring that it is less than or equal to the floating point value 1.5.
Individual modules specify the rules for what types and operators are allowed on given identifiers. See the module documentation for more information.
Type inference#
Modules individually specify how values are typed. For example, the json module extracts all values as strings, and using a filter json foo == 1.5 will perform a string comparison on the value of foo with the string 1.5.
Query structure#
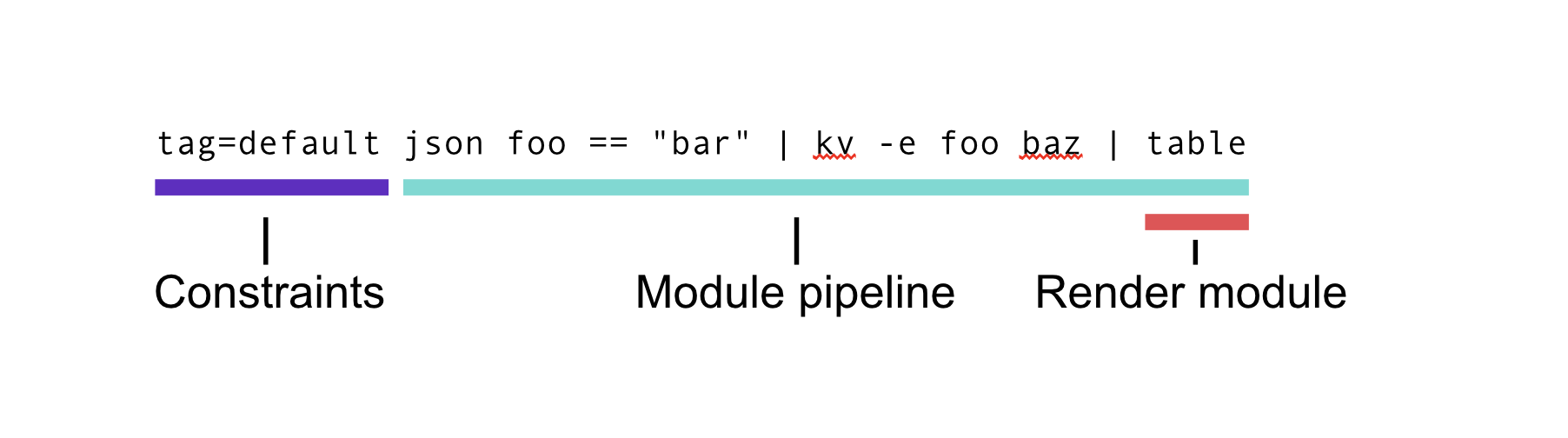
A query is made up of any number of query constraints (such as which tags to pull data from), search modules (arranged in a pipeline), and a render module. Additionally, multiple queries can be packed into a compound query.
Query constraints#
All input before the first module in a query represents the query constraints. Usually this is just the tag(s) to extract. Query constraints are a whitespace-delimited list of key=value pairs. The following constraints are supported.
Constraint |
Description |
Example |
|---|---|---|
tag |
The tag(s) to extract. Supports comma separated lists and wildcards. Defaults to “tag=default” if omitted. |
tag=dns,zeek* |
start |
Provide the query starting timeframe in the query. Supports both concrete timestamps and offsets. If “end” is omitted when “start” is used, “end” will be set to the current time. |
start=”2006-01-02T15:04:05Z”, start=-1h |
end |
Provide the query ending timeframe in the query. Supports both concrete timestamps and offsets. If “start” is omitted when “end” is used, “start” will be set to the current time. |
end=”2006-01-02T15:04:05Z”, end=-1h |
Modules#
Please see the list of modules in the Search section for module specific documentation.
Modules are pipelined functions that extract, transform, and render data. Conceptually, data flows left-to-right in the module pipeline, and modules can drop, pass, modify, or inject data into the pipeline. The last module in the pipeline is the render module (such as table or chart); note that if no render module is explicitly defined, Gravwell will add one automatically. The module pipeline is split by the | character. A module invocation is made up of the module name, optional flags, and optional arguments.
Module name#
The first token of a module invocation is the module name. See the list of modules in the Search section for the list of available modules.
Module flags#
Flags are whitespace-delimited lists of module-specific configuration options. Some flags take arguments, and some modules support multiple invocations of the same flag. See the module documentation for more information on the specific flags for that module.
Flags take two forms. First is a flag with no arguments, such as
kv -q
The second form takes an argument, which must be quoted if it contains any reserved characters or whitespace.
kv -e "my enumerated value"
The first token that does not begin with a hyphen, and is not the argument to a flag, represents the first argument to the module.
Module arguments and semantics#
Module arguments are module-specific lists of tokens containing identifiers, filters, and other keywords. Every token up to the end of the input or the | character is considered an argument to that module. Modules apply their own semantics to their argument tokens. For example, the fields module uses the special characters [ and ] to denote a column offset, while the lookup module uses ( and ) for groups of extractions. Refer to the module documentation for more information.
Renderer#
The last module in a query is always the renderer. Render modules take flags and arguments just like a search module, but must appear at the end of the pipeline.
If no renderer is specified, the text renderer is implied.
Compound queries#
Multiple modules can be grouped into a single compound query using the compound query notation. A compound query takes the form of
@foo{tag=default ...}; @bar{tag=default ...}; tag=default lookup -r @foo | ...
Where @foo, @bar represent the names of “inner” queries. The @ is required. Any query can be specified in the inner query body, enclosed in {}, but the renderer must be the table renderer. Any number of inner queries can be specified. Inner queries and the main query (the final query in the list of queries, which is not wrapped in the @{} notation) are separated by semicolons.
Queries are executed in order, and any later query (including other inner queries) can use the output of an earlier inner query anywhere that a tabular resource can be used (such as the lookup module), by referencing the query by name with the @ symbol.
Query Grammar#
Below is the pbpg representation of the query grammar.
# Query and module grammar
Query = CompoundQuery | QueryStructure
QueryStructure = { Constraint } [ [ "|" ] Module { "|" Module } ]
CompoundQuery = InnerQuery { InnerQuery } QueryStructure
InnerQuery = Whitespace AT QueryName "{" QueryStructure "}" SEMICOLON
Constraint = Whitespace CLvalue "=" CRvalue { "," CRvalue }
ModuleConstraint = Whitespace MCLvalue "=" CRvalue { "," CRvalue }
Module = { ModuleConstraint } Whitespace ( SpecialModule | JSONModule | Hoc | RegularModule ) Whitespace
JSONModule = JSONModuleName { JSONToken }
SpecialModule = SpecialModuleName { SpecialToken }
RegularModule = ModuleName { Token }
JSONToken = RawString | QuotedString | JSONString | ( Op ( QuotedString | RString ) ) | Special
SpecialToken = RawString | QuotedString | RString | ( Op ( QuotedString | RString ) ) | Special
Token = RawString | QuotedString | String | ( Op ( QuotedString | RString ) ) | Special
# Eval grammar
Hoc = ( HocName HocFragment ) | ( HocName EvalFragment )
HocFragment = { HocToken }
HocToken = Whitespace EVLiteral | Identifier | Operator | QuotedString | Number | LPAREN | RPAREN | LCURLY | RCURLY | PIPE
EVLiteral = "$(" EV ")"
EV = ev
Identifier = Letter { LetterDigit }
LetterDigit = Letter | Digit
Letter = letter
Digit = digit
Operator = "<<" | ">>" | "<=" | ">=" | "+=" | "-=" | "&&" | "||" | "++" | "--" | "==" | "!=" | "!~" | "~" | "+" | "-" | "*" | "/" | "%" | "&" | "^" | "<" | ">" | "=" | "!" | "[" | "]" | "," | ";" | "." | ":" | "?"
LPAREN = lparen
RPAREN = rparen
LCURLY = lcurly
RCURLY = rcurly
PIPE = pipe
Number = Hex | Decimal
Decimal = Digit { Digit } [ Dot { Digit } ]
Hex = hex
Dot = dot
EvalFragment = evalfragment
# Lexer invocations
Special = Whitespace "(" | ")" | ";" | "=" | "<" | "!" | ">" | "~" | "%" | "^" | "&" | "*" | "," | "+" | "." | ":" | "[" | "]" | "/"
Op = Whitespace "<=" | ">=" | "==" | "!=" | "~" | "!~" | "<" | ">"
Comments#
Gravwell supports two types of comments.
Any input between ANSI-C style comment specifiers
/* */.Line comments, which begin with a double slash
//and stop at the end of the line.Comments are not considered part of the input to Gravwell.
For example,
is implicitly reduced to
A comments is defined as