
JSON#
The json module is used to extract and filter data from search entries into enumerated values for later use. JSON is an excellent data format for dynamic exploration as the data is self-describing. The JSON module can extract items and rename them, or filter based on the extracted value. Filtering directly within the JSON module provides a very high speed and intuitive way to select data of a specific format.
Note
The json module does not unescape extracted fields that may have been escaped in order to adhere to the JSON specification. You can use the unescape module to unescape extracted fields.
Supported Options#
-e <arg>: The “-e” option operates on an enumerated value instead of on the entire record.-s: The “-s” option informs the json module that we are in strict mode, meaning that if any field extraction fails, drop the entire entry. If you sayjson -s foo, any entry which doesn’t contain a field named “foo” will be dropped; conversely,json foosimply extracts “foo” when possible and drops nothing. Specifyingjson -s foo barmeans each entry must contain fields named “foo” and “bar”.-x <arg>: The “-x” option tells the module to expand the contents of a JSON array into multiple entries, one per array value. The rest of the entry remains the same. The argument can be the output name of one of the current extractions, or it can be an enumerated value. Thus, bothtag=foo json -x bar foo.barandtag=foo json foo.bar | json -x barare valid invocations.
Filtering Operators#
The JSON module can filter based on equality and substring matching. If a filter is enabled that specifies equality (“equal” or “not equal”), any entry that fails the filter specification will be dropped entirely.
Operator |
Name |
Description |
|---|---|---|
== |
Equal |
Field must be equal |
!= |
Not equal |
Field must not be equal |
~ |
Subset |
Field contains the value |
!~ |
Not Subset |
Field does NOT contain the value |
Note
If a field is specified as not equal “!=” and the field does not exist, the field is not extracted but the entry won’t be dropped. If you wish to drop the entries which don’t contain the field at all, use the -s flag.
Examples#
To find the most prolific Reddit posters, the following search extracts the “Author” field from each Reddit post into a new enumerated value, then counts the occurrence of each author and puts it into a table:
tag=reddit json Author | count by Author | table Author count
The module can also descend multiple layers into the JSON entry. For example, in the Shodan data we ingest for testing, we can extract the “region code” from entries to discover where the endpoint resides. If we want to learn which states have the most AT&T U-verse customers, we can issue the following search:
tag=shodan grep "AT&T U-verse" | json location.region_code | count by region_code | table region_code count
Using Enumerated Values#
We can also operate on enumerated values rather than the full entry data if desired; for instance, if an XML entry contains json within it:
<System><Data>{ "domain": "gravwell.io" }</Data></System>
We can use the following command to extract the JSON from within the XML as an enumerated value named “Data”, then apply the json module to parse out the domain value into another enumerated value named “domain”:
xml System.Data | json -e Data domain
Renaming Extractions#
Enumerated value names are derived by the last name in a JSON specification, in the earlier example which extracted the region_code field the output is populated in the “region_code” enumerated value. Output enumerated value names can be overridden with an “as” argument. The following example extracts the domain member from the Data enumerated value and assigns it into a new enumerated value named “dd”:
json -e Data domain as dd
Using the filter operator we can extract the Data field, but only when the domain is not the value “google.com.” Filters can be combined with renaming.
json -e Data domain != "google.com" as dd
Quoting Rules#
The JSON format is extremely liberal and allows names of all types, including characters Gravwell usually treats as separators such as ‘.’ and “-”. In cases where the JSON name contains such characters, wrap the individual field in double-quotes to parse it as a single token. For example, this JSON string contains a dot character in a field name:
{ "subfield.op": "stuff", "subfield.type": "int", "subfield.value": 99}
An example json module argument to extract the subfield.op member would be:
json "subfield.op" as sop
Similarly, consider the following nested structure:
{ "fields": { "search-id": 1234, "search-type": "background" } }
Because search-id and search-type contain a dash character, they should be wrapped in quotes when used:
json fields."search-id" fields."search-type" as type | count by "search-id",type | table "search-id" type count
Arrays#
The json module can extract elements from arrays. Consider the following structure:
{ "uid": 1, "groups": [17,3] }
To extract the first group from the array of groups, we can say:
json groups.[0] as gid
(If the extraction is not renamed, the enumerated value will be named “[0]” which is very clumsy)
To expand an array, we extract the array and pass the output name to the -x flag:
json -x groups groups uid
This will turn the single entry into two entries, one with enumerated values uid=1 and groups=17, one with uid=1 and groups=3.
Note
When expanding an array via the -x flag, the underlying Data field and all other enumerated values are duplicated intact; only the contents of the array enumerated value change.
We can also extract components from within array elements:
{ "Metadata": [ {"Value": "john"}, {"Value": "Albuquerque"} ] }
json Metadata.[0].Value as Username
Empty array indices#
If the array index syntax is used without an index, the json module will find and return the first array element that satisfies the extraction. For example, given the input:
{ "Metadata": [ {"Value": "john"}, {"Value": "Albuquerque", "State": "NM"} ] }
The query
json Metadata.[].State
Will iterate through the array until it finds the first object with a “State” field, and extract that.
Empty Fields and the Strict Flag#
The module makes a distinction between fields which are not defined and fields which contain the empty string. Consider the following entries:
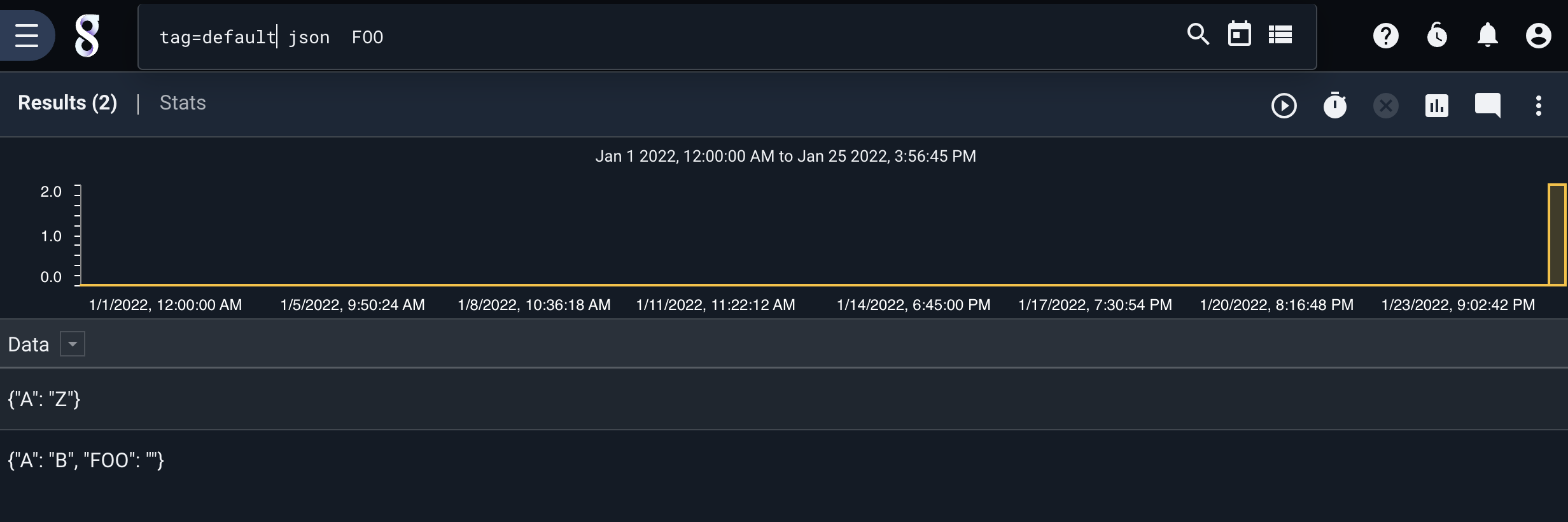
{"A": "B", "FOO": ""}
{"A": "Z"}
The first entry contains a field named “FOO” which is an empty string. The second entry does not contain a “FOO” field at all.
This query will drop the first entry but pass the second:
json FOO!=""
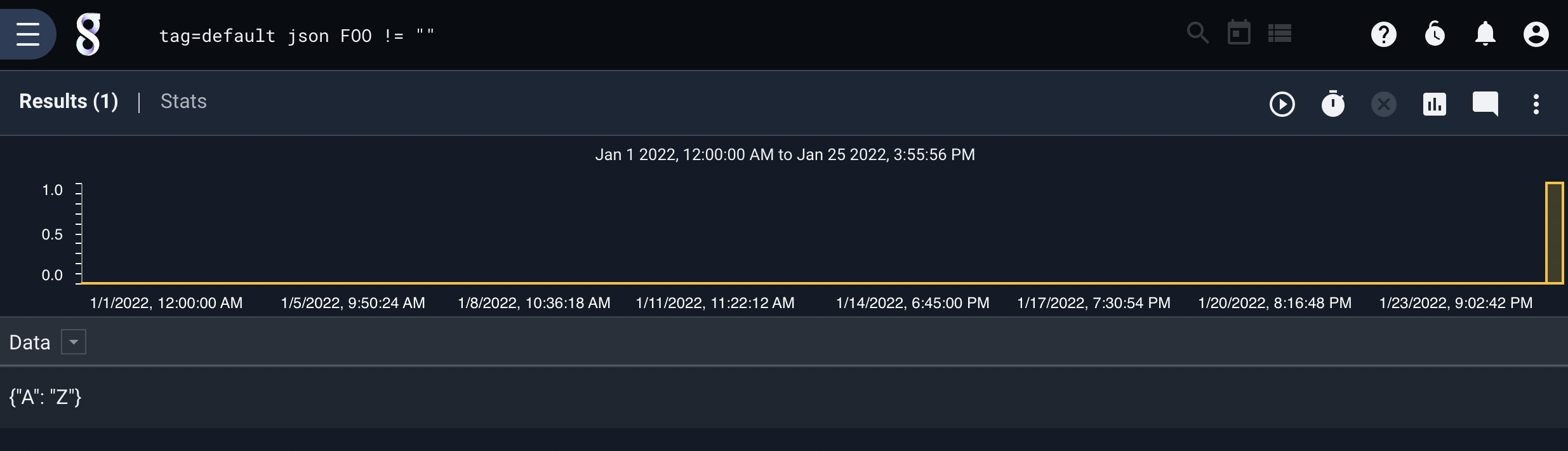
The following query will drop the second entry but pass the first, extracting an empty string into an enumerated value named FOO:
json -s FOO
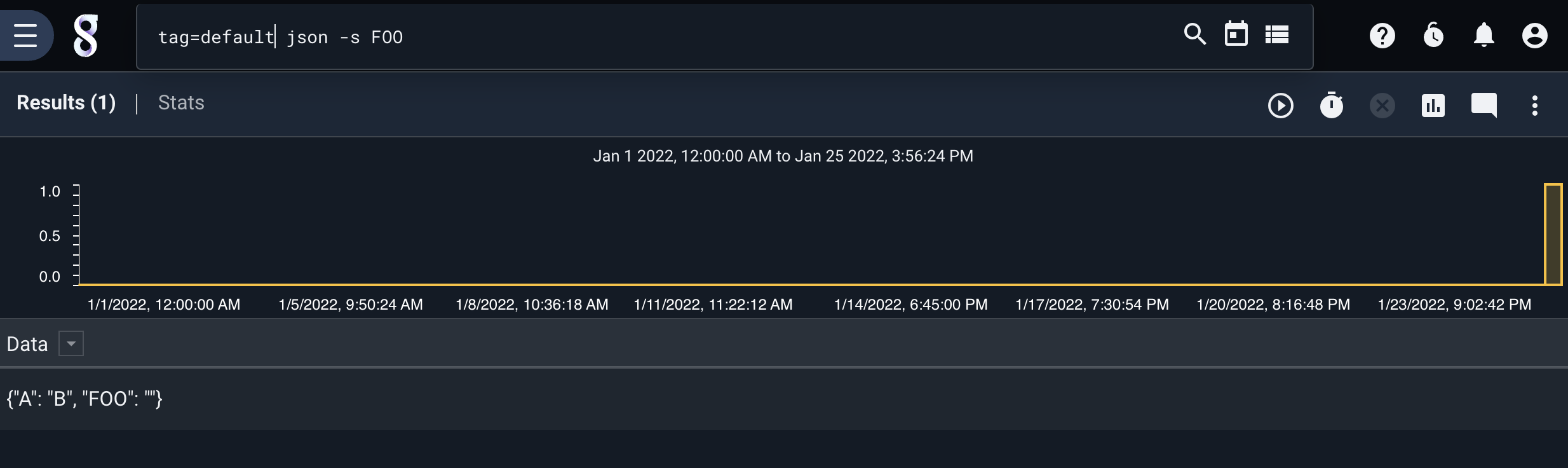
This query will pass both entries, extracting FOO from the first entry:
json FOO
This query will drop both entries, because the != filter excludes the first entry and the strict flag excludes the second (because it lacks a field named “FOO”):
json -s FOO!=""