
Quick Start#
This section contains basic “quick start” instructions for getting Gravwell up and running on a single server. These instructions support the most common use case and act as an introduction to Gravwell. Please note, the “Quick Start” instructions do not take advantage of the more advanced Gravwell features regarding distributed search and storage that are available in the Cluster Edition. If you require a more advanced setup, please review the Advanced Topics section of this guide.
This guide is suitable for Community Edition users as well as users with a paid single-node Gravwell subscription.
You may find the installation checklist and the glossary useful companions to this document.
If you are interested in a complete training package, please see the complete training PDF. The Gravwell training PDF is the complete training manual which is paired with labs and exercises. The exercises are built from the open source Gravwell Training repository.
Note
Community Edition users will need to obtain their own license from https://www.gravwell.io/download before beginning installation. Paid users should already have received a license file via email.
System Requirements#
Hardware Estimator#
We strongly recommend at least 4GB of RAM and 2 CPU cores to run Gravwell Community Edition; this should be sufficient up to the CE ingest limit. If you have a paid license, you should scale up your hardware as your daily data ingest increases. In general, we recommend the following rules of thumb for indexers:
One CPU core per 30 GB/day ingest.
1 GB of RAM per 6 GB/day ingest.
Note that as your ingest scales to the hundreds or thousands of gigabytes per day, you’ll usually want more cores and memory per indexer, as queries simply tend to become more “expensive” – and you’re often running more of them in such a large deployment!
If you’re deploying a cluster, your webserver should be roughly similar to your indexers in terms of CPU and memory. Webservers don’t need much storage, but will benefit from having /opt/gravwell on a fast disk like an NVMe drive.
Below is a simple calculator for estimating your hardware needs:
Expected Ingest Per Day (GB) |
|
Recommended # of Indexers |
– |
Recommended Per-Indexer Core Count |
– |
Recommended Per-Indexer RAM |
– GB |
Recommended Webserver Core Count |
– |
Recommended Webserver RAM |
– GB |
Note
These are only very rough estimates, and of course performance will vary based on the hardware you select: eight Xeon Ivy Bridge cores are not comparable to eight Epyc Turin or Xeon Granite Rapids cores!
You can estimate your storage requirements using the following calculator:
Daily Data Volume (GB) |
|
Required Retention (days) |
|
Estimated Compression Factor† |
|
Acceleration Storage Type‡ |
|
Recommended Storage Size |
– GB |
† Value between 0 and 1.0 representing how compressed the raw data will be on disk. Most text-based logs compress to about 20% of their size, so we use a default of 0.2. If you intend to disable compression entirely, or if you’ll be ingesting lots of binary data, set this to 1.0.
‡ We assume fulltext acceleration for this calculator. Storing the acceleration data using true indexing is the most expensive; using a bloom filter instead can reduce storage overhead significantly at the cost of potentially worse performance. Disabling acceleration entirely (by selecting “None”) is usually not recommended, as it makes queries very disk-intensive.
Browser Support#
To keep Gravwell fast and secure, we adhere to standards set by the Angular web application framework. This means we focus on “evergreen” browsers. The browsers that auto-update and stay modern.
List of Fully Supported Browsers#
As of version 5.9.0, Gravwell supports the two most recent versions of:
Chrome
Firefox (and the extended support release)
Edge
Safari
Safari on iOS
Android
A more detailed description of supported browsers can be found in the “Core browser set” section of this page: Baseline, Supported browsers.
Using other browsers?#
You’re more than welcome to use other browsers (Brave, Opera) or older versions, but you’ll be squarely off the beaten path. It might work just fine, but a smooth ride is not guaranteed.
Installation#
Installing Gravwell on a single machine is quite simple–just follow the instructions in this section. For more advanced environments involving multiple systems, review the Advanced Topics section.
Gravwell is distributed in four ways: via a Docker container, via a distribution-agnostic self-extracting installer, via a Debian package repository, and via a Redhat package repository. We recommend using the Debian repository if your system runs Debian or Ubuntu, the Redhat packages if your system runs RHEL, CentOS, or SuSE, and the self-extracting installer otherwise. The Docker distribution is also useful for those familiar with Docker. Gravwell has been tested on all of the major Linux distributions and runs well, but Ubuntu Server LTS is preferred. Help installing Ubuntu can be found at https://tutorials.ubuntu.com/tutorial/tutorial-install-ubuntu-server.
Debian repository#
Installing from the Debian repository is quite simple. We need to take a few steps first to add Gravwell’s PGP signing key and Debian package repository, but then it’s just a matter of installing the gravwell package.
Set up Gravwell’s Debian Repository#
First, we’ll set up the Gravwell Debian repository by installing some prerequisite packages, fetching our signing key, and installing a file describing the repository into the APT configuration directory. Run the following commands as the root user:
apt install apt-transport-https gnupg wget
wget -O /usr/share/keyrings/gravwell.asc https://update.gravwell.io/debian/update.gravwell.io.gpg.key
echo 'deb [ arch=amd64,arm64 signed-by=/usr/share/keyrings/gravwell.asc ] https://update.gravwell.io/debian community main' > /etc/apt/sources.list.d/gravwell.list
Update Apt and Install Gravwell#
apt update && apt install gravwell
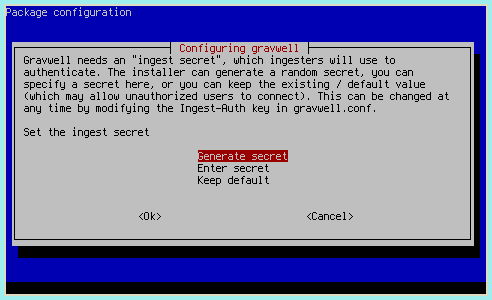
The installation process will prompt to set some shared secret values used by components of Gravwell. We strongly recommend allowing the installer to generate random values (the default) for security.
Redhat/CentOS Repositories#
Gravwell is available as a yum repository for both Redhat and CentOS Linux distributions. To use the Gravwell yum repository, add the following stanza to your yum.conf (located in /etc/yum.conf)
[gravwell]
name=gravwell
baseurl=https://update.gravwell.io/rhel
gpgkey=https://update.gravwell.io/rhel/gpg.key
Next perform the following:
yum update
yum install -y gravwell
Once installed you will have to bump the CentOS firewall for web ports, executing the following:
sudo firewall-cmd --zone=public --add-service=http --permanent
sudo firewall-cmd --zone=public --add-service=https --permanent
sudo firewall-cmd --reload
You should now be able to access the Gravwell web interface on the IP assigned to the CentOS/RHEL system.
Docker Container#
Gravwell is available on DockerHub as a single container including both the webserver and indexer. Refer to the Docker installation instructions for detailed instructions on installing Gravwell in Docker.
Self-contained Installer#
For non-Debian systems, download the self-contained installer from our downloads page.
Then run the installer:
sudo bash gravwell_X.X.X.sh
Follow the prompts and, after completion, you should have a running Gravwell instance.
Note
If your distribution does not use systemd, you will have to start the Gravwell processes manually after installation. Please contact support@gravwell.io if you need help.
Configuring the License#
Once Gravwell is installed, open a web browser and navigate to the server (e.g. http://localhost/). It should ask if you have a license file already (if you’ve already signed up for CE) or if you need to get one:
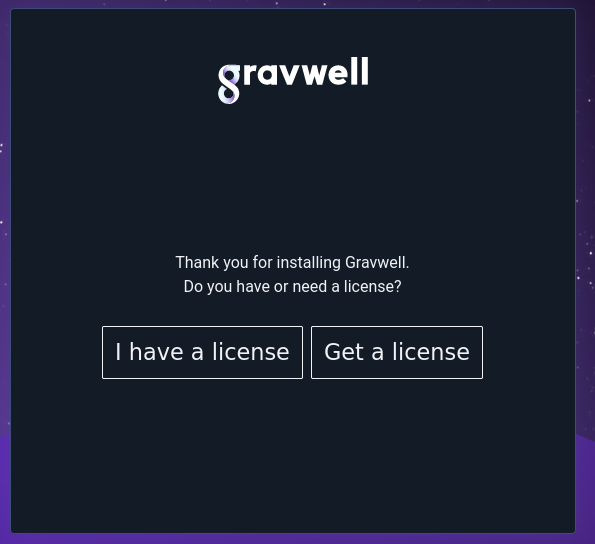
Clicking “Get a license” will take you to a form where you can sign up for community edition and get a license emailed to you:
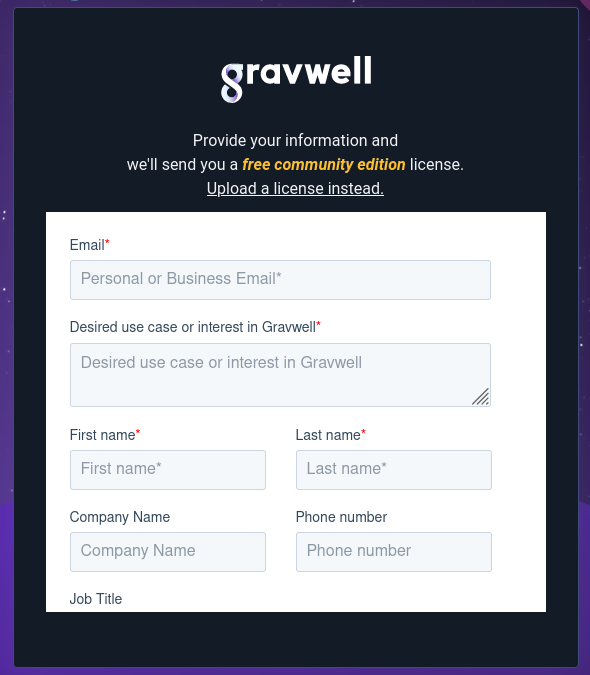
Once you submit that form, or if you click “I have a license”, you will be taken to the EULA page:
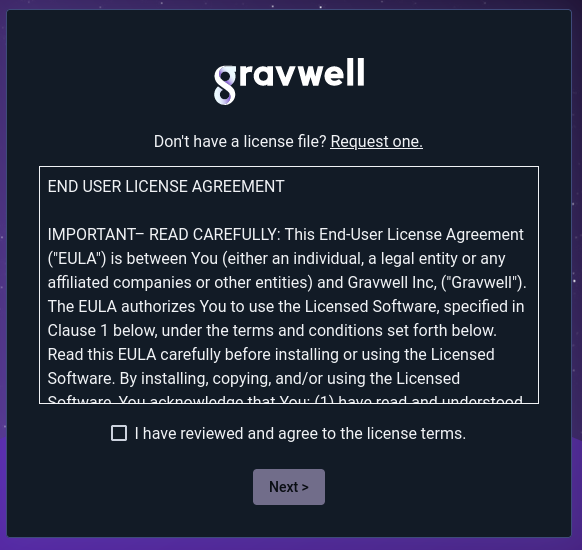
After agreeing to the EULA, you may upload your license:
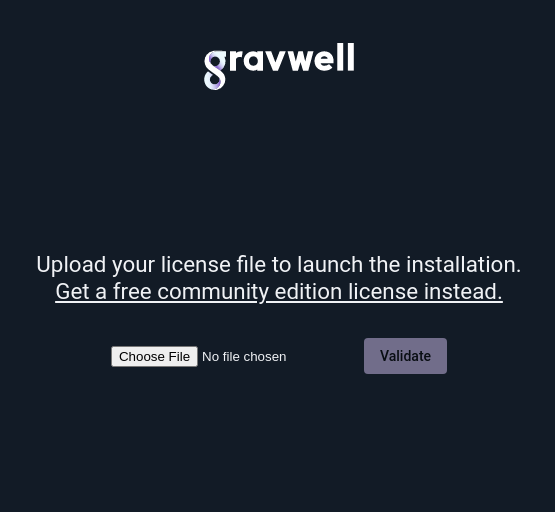
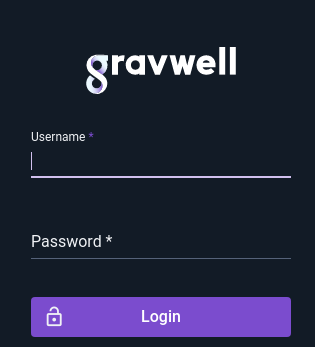
Once the license is uploaded and verified, Gravwell should present a login screen. Log in as “admin” with the password “changeme”.
Attention
The default username/password combination for Gravwell is admin/changeme. We highly recommend changing the admin password as soon as possible! This can be done by choosing “Account Settings” from the navigation sidebar or clicking the “user” icon in the upper right.
Configuring Ingesters#
A freshly installed Gravwell instance, by itself, is boring. You’ll want some ingesters to provide data. You can either install packages from the repositories or head over to the Downloads page to fetch self-extracting installers for each ingester.
The ingesters available in the Debian repository can be viewed by running apt-cache search gravwell:
root@debian:~# apt-cache search gravwell
gravwell - Gravwell data analytics platform (gravwell.io)
gravwell-azure-event-hubs - Gravwell ingester for Azure Event Hubs
gravwell-collectd - Gravwell collectd ingester
gravwell-crash-reporter - Gravwell crash reporter service
gravwell-datastore - Gravwell datastore service
gravwell-federator - Gravwell ingest federator
gravwell-file-follow - Gravwell file follow ingester
gravwell-http-ingester - Gravwell HTTP ingester
gravwell-ipmi - Gravwell IPMI Ingester
gravwell-kafka - Gravwell Kafka ingester
gravwell-kafka-federator - Gravwell Kafka federator
gravwell-kinesis - Gravwell Kinesis ingester
gravwell-loadbalancer - Gravwell load balancing service
gravwell-msgraph - Gravwell ingester for Microsoft Graph API
gravwell-netflow-capture - Gravwell netflow ingester
gravwell-network-capture - Gravwell packet ingester
gravwell-o365 - Gravwell Office 365 log ingester
gravwell-offline-replication - Gravwell offline replication service
gravwell-packet-fleet - Gravwell Packet Fleet ingester
gravwell-pubsub - Gravwell ingester for Google Pub/Sub streams
gravwell-s3 - Gravwell S3 ingester
gravwell-shodan - Gravwell Shodan ingester
gravwell-simple-relay - Gravwell simple relay ingester
gravwell-sqs - Gravwell SQS ingester
gravwell-tools - Miscellaneous Gravwell tools
If you install them on the same node as the main Gravwell instance, they should be automatically configured to connect to the indexer, but you’ll need to set up data sources for most. See the ingester configuration documents for instructions on that.
We highly recommend installing the File Follow ingester (gravwell-file-follow) as a first experiment; it comes pre-configured to ingest Linux log files, so you should be able to see some entries immediately by issuing a search such as tag=auth:
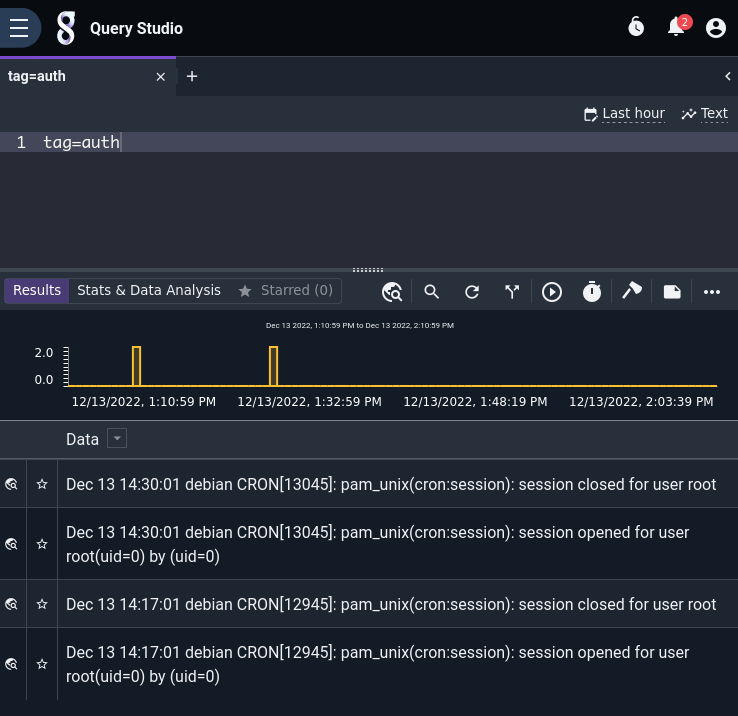
File Ingester#
The File Follower ingester is one of the simplest ways to start getting logs into Gravwell, because it comes pre-configured to ingest standard Linux log files.
If you’re using the Gravwell Debian repository, installation is just a single apt command:
apt-get install gravwell-file-follow
Otherwise, download the installer from the Downloads page. Using a terminal on the Gravwell server, issue the following command as a superuser (e.g. via the sudo command) to install the ingester:
root@gravserver ~ # bash gravwell_file_follow_installer.sh
If the Gravwell services are present on the same machine, the installation script will automatically extract and configure the Ingest-Auth parameter and set it appropriately. However, if your ingester is not resident on the same machine as a pre-existing Gravwell backend, the installer will prompt for the authentication token and the IP address of the Gravwell indexer. You can set these values during installation or leave them blank and modify the configuration file in /opt/gravwell/etc/file_follow.conf manually. See the ingesters documentation for more information on configuring the ingester.
Simple Relay Ingester#
Gravwell’s ‘Simple Relay’ ingester can ingest line-delimited or syslog-formatted messages over the network. It’s another good way to start getting data into Gravwell from your existing data sources.
If you’re using the Gravwell Debian repository, installation is just a single apt command:
apt-get install gravwell-simple-relay
Otherwise, download the installer from the Downloads page. Using a terminal on the Gravwell server, issue the following command as a superuser (e.g. via the sudo command) to install the ingester:
root@gravserver ~ # bash gravwell_simple_relay_installer.sh
If the Gravwell services are present on the same machine, the installation script will automatically extract and configure the Ingest-Auth parameter and set it appropriately. However, if your ingester is not resident on the same machine as a pre-existing Gravwell backend, the installer will prompt for the authentication token and the IP address of the Gravwell indexer. You can set these values during installation or leave them blank and modify the configuration file in /opt/gravwell/etc/simple_relay.conf manually. See the ingesters documentation for more information on configuring the ingester.
Ingester Notes#
If your installation is entirely contained on one machine, as it is in these quick start instructions, the ingester installers will extract the configuration options and configure themselves appropriately. If you are using an advanced setup where not all Gravwell components are running on a single system, review the ingesters section of the documentation.
You now have the File Follow and Simple Relay services running on the Gravwell server. File Follow will automatically ingest log entries from some files in /var/log/. By default it ingests /var/log/auth.log with the “auth” tag, /var/log/dpkg.log with the “dpkg” tag, and /var/log/dmesg and /var/log/kern.log with the “kernel” tag.
Simple Relay will ingest syslog entries sent to it on TCP port 601 or UDP port 514; these will be tagged with the “syslog” tag. The Simple Relay config file also contains an entry to listen for any line-delimited data on port 7777. This can be disabled if you only intend to use syslog; simply comment out the [Listener "default"] section in the config file and restart the simple relay service. The configuration file for this service is located at /opt/gravwell/etc/simple_relay.conf. See the Simple Relay section of the Ingesters documentation for advanced configuration options.
Feeding Data into Gravwell#
This section provides basic instructions for sending data into Gravwell. Review the ingesters section for instructions for setting up other data ingesters.
The “Ingesters & Federators” page (in the “Systems & Health” section of the main menu) can help you see if the ingesters are connected and the Gravwell server is receiving any data. If no data is reported and you think that is an error, double-check that the ingesters are running (ps aux | grep gravwell should show gravwell_webserver, gravwell_indexer, gravwell_simple_relay, and gravwell_file_follow) and that their configuration files are correct.
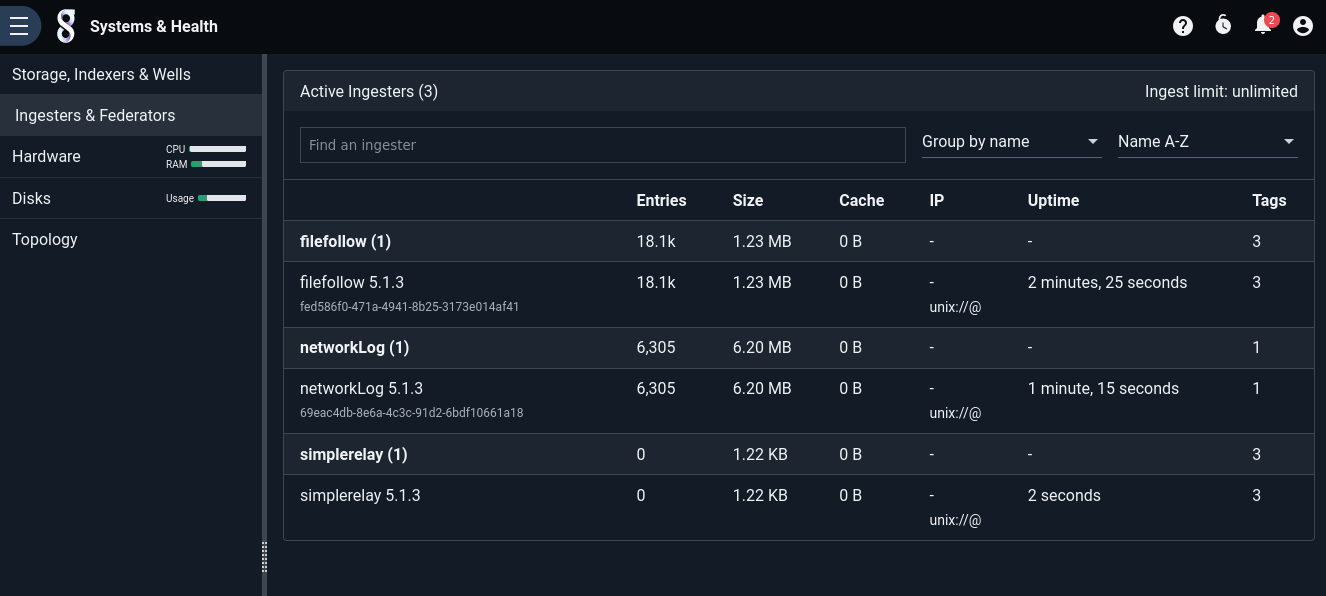
Ingesting Syslog#
Once the Gravwell server is installed and the Simple Relay text ingester service is running, you can start feeding any log or text data into Gravwell via the syslog protocol. By default, the Simple Relay ingester listens for TCP syslog on port 601 and UDP syslog on port 514.
To send the syslog entries from a Linux server running rsyslog to Gravwell, create a new file named /etc/rsyslog.d/90-gravwell.conf on the server and paste the following line into it for UDP syslog, taking care to modify the hostname gravwell.example.com to point at your own Gravwell instance:
*.* @gravwell.example.com;RSYSLOG_SyslogProtocol23Format
or use this instead for TCP syslog:
*.* @@gravwell.example.com;RSYSLOG_SyslogProtocol23Format
(note the use of @ in the UDP configuration vs. @@ for TCP)
Then restart the rsyslog daemon:
sudo systemctl restart rsyslog.service
Many Linux services (such as DNS, Apache, ssh, and others) can be configured to send event data via syslog. Using syslog as a “go between” for those services and Gravwell is often the easiest way to configure those services to send events remotely.
Adding this line to an Apache configuration entry, for example, will send all Apache logs to rsyslog, which will forward them to Gravwell:
CustomLog "|/usr/bin/logger -t apache2.access -p local6.info" combined
Archived Logs#
The Simple Relay ingester can also be used to ingest any old logs (Apache, syslog, etc) that are sitting around on the filesystem. By utilizing a basic network comms tool like netcat, any data can be shoveled into the Simple Relay ingester’s line-delimited listener. By default Simple Relay listens for line-delimited entries on TCP port 7777.
For example, if you have some old Apache log files you’d like to analyze in Gravwell, you could run a command like this to ingest them:
user@webserver ~# cat /tmp/apache-oct2017.log | nc -q gravwell.server.address 7777
Note
If you are ingesting a very large set of logs in multiple files, we recommend using the MassFileIngester utility to pre-optimize and ingest en masse, rather than relaying through the Simple Relay ingester.
Network Packet Ingester#
A primary strength of Gravwell is the ability to ingest binary data. The network ingester allows you to capture full packets from the network for later analysis; this provides much better flexibility than simply storing Netflow or other condensed traffic information at the cost of increased storage use.
If you’re using the Gravwell Debian repository, installation is just a single apt command:
apt-get install libpcap0.8 gravwell-network-capture
Otherwise, download the installer from the Downloads page. To install the network ingester, simply run the installer as root (the file name may differ slightly):
root@gravserver ~ # bash gravwell_network_capture_installer.sh
The network ingester requires the libpcap shared libraries. If using the standalone installer, you’ll need to make sure you have also installed the libraries; the package is libpcap0.8 on Debian.
If the ingester is on a machine with a Gravwell backend already installed, the installer should automatically pick up the correct Ingest-Secrets value and populate the config file with it. In any case, review the configuration file in /opt/gravwell/etc/network_capture.conf before running. Make sure at least one “Sniffer” section is uncommented, with the Interface field set to one of your system’s network interfaces. For more information, see the Ingesters documentation
Note
The Debian package and the standalone installer should both prompt for a device from which to capture. If you wish to change your selection, open /opt/gravwell/etc/network_capture.conf, set the desired interface, and run service gravwell_network_capture restart to restart the ingester.
Searching#
Once the Gravwell server is up and running and receiving data, the power of the search pipeline is made available.
Here are a few example searches based on the type of data ingested in this quick-start setup. For these examples, we assume there is syslog data being generated by Linux servers and ingested via the Simple Relay text ingester, and that packets are being captured from the network as described in the preceding sections.
Syslog Example#
Syslog is a core component of any Unix logging and auditing operation. It is important to have complete visibility into logins, crashes, sessions, or any other service action while debugging and defending Unix infrastructure. Gravwell makes it easy to get syslog data off your many remote machines into a central location and ready for query. For this example we will search SSH logs and examine how an administrator or security professional might gain visibility into SSH activity.
In this example, servers are configured to send SSH login data to a Gravwell instance. If you want to see a list of all SSH-related entries, you can issue a search like:
tag=syslog grep ssh
The breakdown of the search command is as follows:
tag=syslog: Only look at data tagged “syslog”. The SimpleRelay ingester is set up to tag data with the “syslog” tag when it comes in via TCP port 601 or UDP port 514.grep ssh: The “grep” module (named after the similar Linux command) searches for specific text. In this case, the search is looking for any entry that contains “ssh” in it.
The search results come back as an overview graph and a series of log entries. The overview graph shows the frequency plot of matching records that made it through the pipeline. This graph can be used to identify the frequency of log entries and to navigate around the time window of the search, narrowing down the view without re-issuing the search. Nearly every search has the ability to refocus and adjust the time window; only searches which alter the order of time do not have the overview graph.
Here are see the results of all entries containing “ssh”:
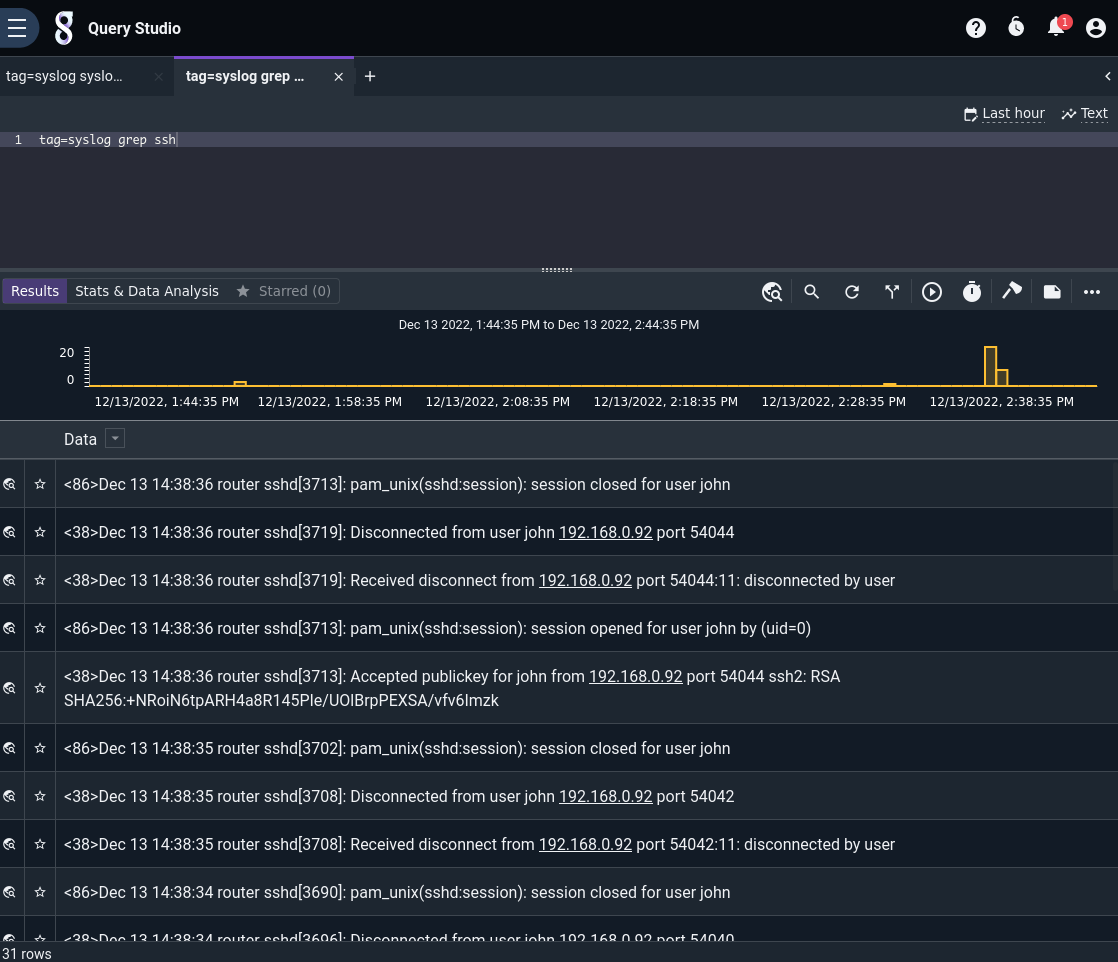
These results might give a very broad insight, but to truly extract useful information we need to refine our search. For this example, we will extract successful SSH logins. We’ll also extract some particular fields from the log records to make displaying the results easier:
tag=syslog syslog Appname==sshd Message~Accepted
| regex -e Message "Accepted\s(?P<method>\S+)\sfor\s(?P<user>\S+)\sfrom\s(?P<ip>\S+)"
Breaking down the search:
tag=syslog: Limit searches to data tagged “syslog”syslog Appname==sshd Message~Accepted: This will invoke the syslog module to filter to only syslog messages generated by the “sshd” application and contain the string “Accepted” in the Message bodyregex -e Message "Accepted\s(?P<method>\S+)\sfor\s(?P<user>\S+)\sfrom\s(?P<ip>\S+)": This is a regular expression operates on just the Message body which was extracted using the syslog module. We extract the user, IP, and method of successful login.
The results are filtered down to only logins:
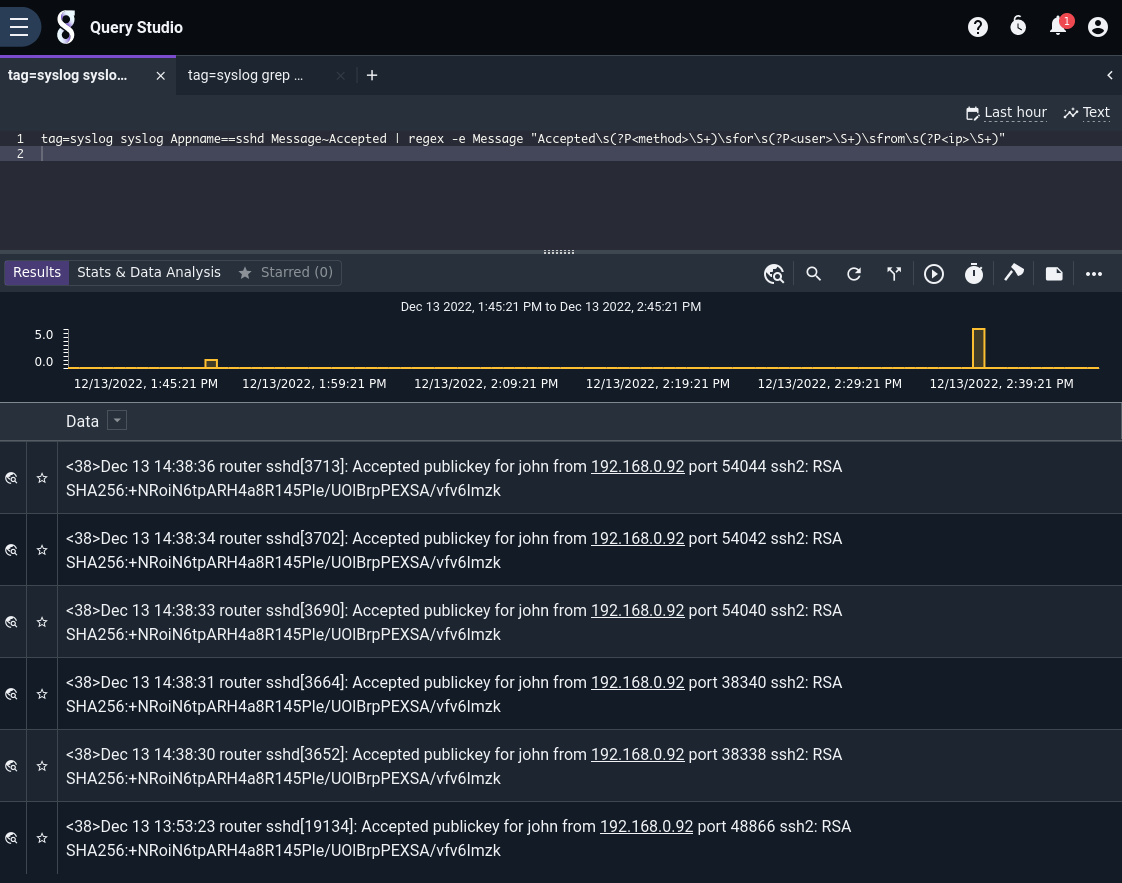
We can specify a render module at the end of the query to change how results are displayed. If we add | table at the end, the table renderer will automatically display all extracted enumerated values:
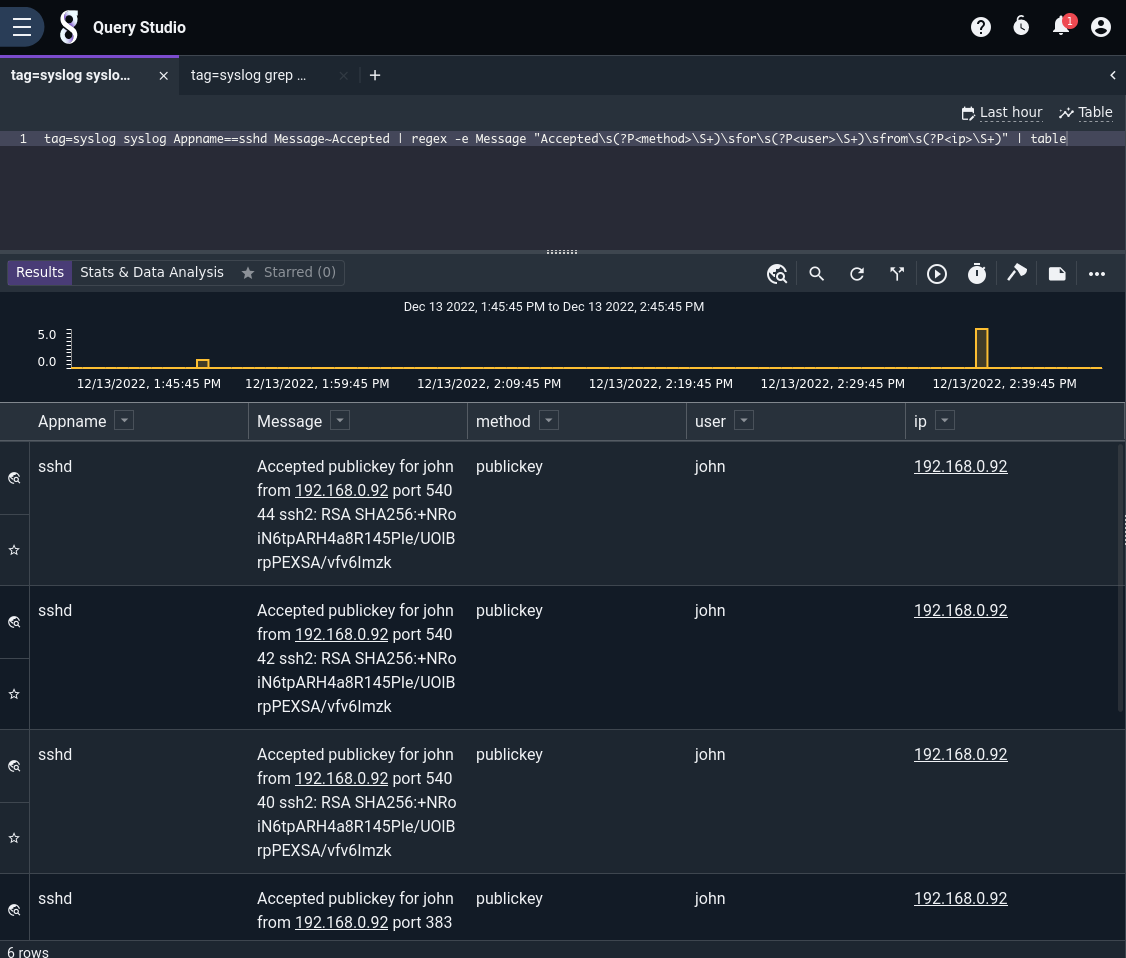
If you want a chart of all the usernames that have logged in, you could issue the following search:
tag=syslog syslog Appname==sshd Message~Accepted
| regex -e Message "Accepted\s(?P<method>\S+)\sfor\s(?P<user>\S+)\sfrom\s(?P<ip>\S+)"
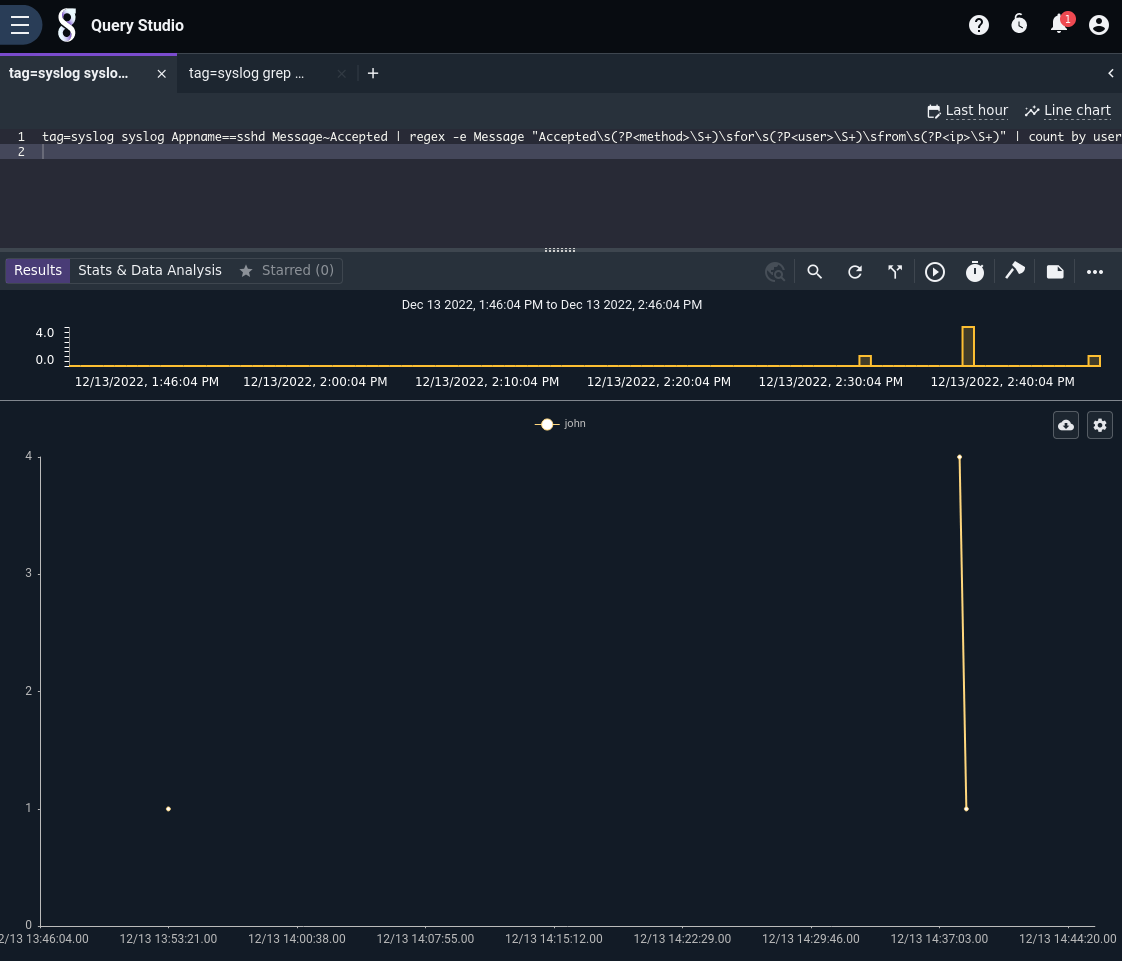
| count by user | chart count by user
The breakdown of the new search query items is as follows:
count by user: Thecountmodule will count how many times eachuservalue (as extracted by regex) appears.chart count by user: Pipe the output of the count module into a charting renderer, drawing a separate line per user with magnitude determined by the count module’s results.
The results show a time plot of user logins during the search timeframe. You can change the graph type to get different views into the data as well as use the overview chart to select smaller timeframes of the results. Looks like “john” is the only user to log in lately!
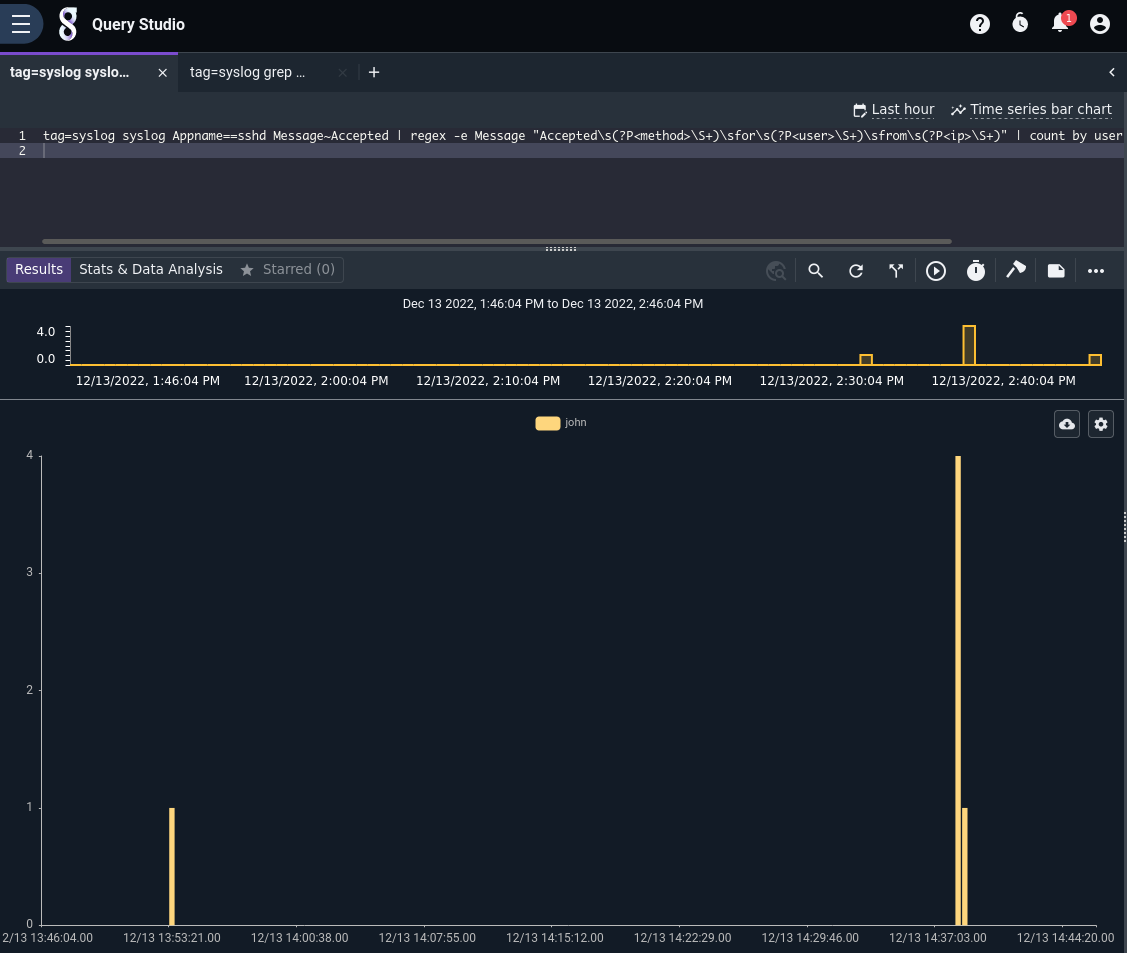
You can also click on the chart type menu (the zig zag line labeled “Line chart” near the upper right) and change the type of chart. Here is the exact same data displayed in a time-series bar chart:
Network Examples#
Consider an example home network in which the user has set up the packet capture ingester on their Linux router, thus capturing all packets to and from the Internet. We can use this data to analyze use patterns, such as web traffic. The example house uses a 192.168.0.0/16 network subnet. The following search will show which PCs are generating the most HTTPS traffic and when:
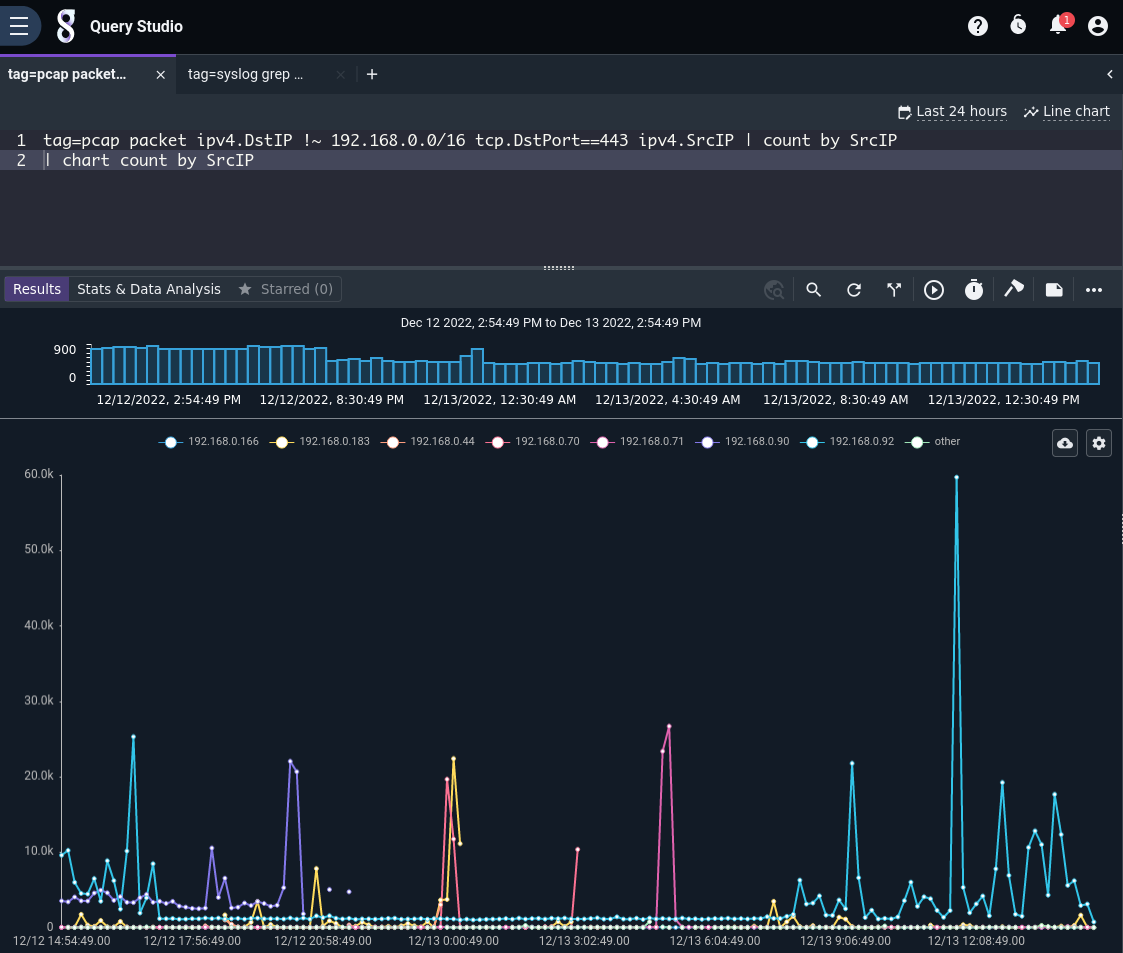
tag=pcap packet ipv4.DstIP !~ 192.168.0.0/16 tcp.DstPort==443 ipv4.SrcIP
| count by SrcIP | chart count by SrcIP
A review of the search command is as follows:
tag=pcap: Tells Gravwell to only search through items tagged ‘pcap’.packet: Invokes the packet parsing search pipeline module and enables the rest of the options in this command.ipv4.DstIP !~ 192.168.0.0/16: The Gravwell packet parser splits out a packet into its various fields. In this case, the search is comparing Destination IPs and looking for those not in the 192.168.x.x class B subnet.tcp.DstPort == 443: Specifies a destination port. This will filter only packets destined for port 443, used by most modern web traffic.ipv4.SrcIP: Specifying this field without a comparison operator tells the packet parser to extract and place the source IP into the pipeline.
count by SrcIP: Pipe the filtered results from the packet parser into the math count module and tell it to count how many times each source IP appears.chart count by SrcIP: Pipe the count results into the charting renderer for display, drawing a separate line for each source IP value. By default it will draw separate lines for the top 7 SrcIPs and group the rest into “other”.
Results: We see several systems sending traffic to port 443. The IP represented in light blue (192.168.0.92) has been active since about 8 in the morning, and was active the previous afternoon… which makes sense, because it’s a work computer!
For more details on using the packet parsing search module, see the packet search module documentation.
Dashboards#
Dashboards are aggregated views of searches that provide a view into multiple aspects of the data at once.
Navigate to the “Dashboards” page (use the menu at top-left) and click the “+Add” button to create a new dashboard – call it “SSH auth monitoring”. Then, add a search. For this example, use the SSH authentication search from earlier. Re-issue that search and from the results screen, use the 3-dot menu in the upper right to choose “Add to Dashboard” and select the new dashboard. A popup in the lower right should inform you that the search was added to the dashboard and provide a link to go to that dashboard; click the link.
The dashboard should have automatically created a tile for the search, but you may wish to resize it. You can change how the tile is displayed by selecting “Edit tile” from the tile’s menu.
Dashboards in Action#
One common use case for Gravwell is keeping track of network activity. Here we see a dashboard that reports on network traffic based on Zeek connection logs
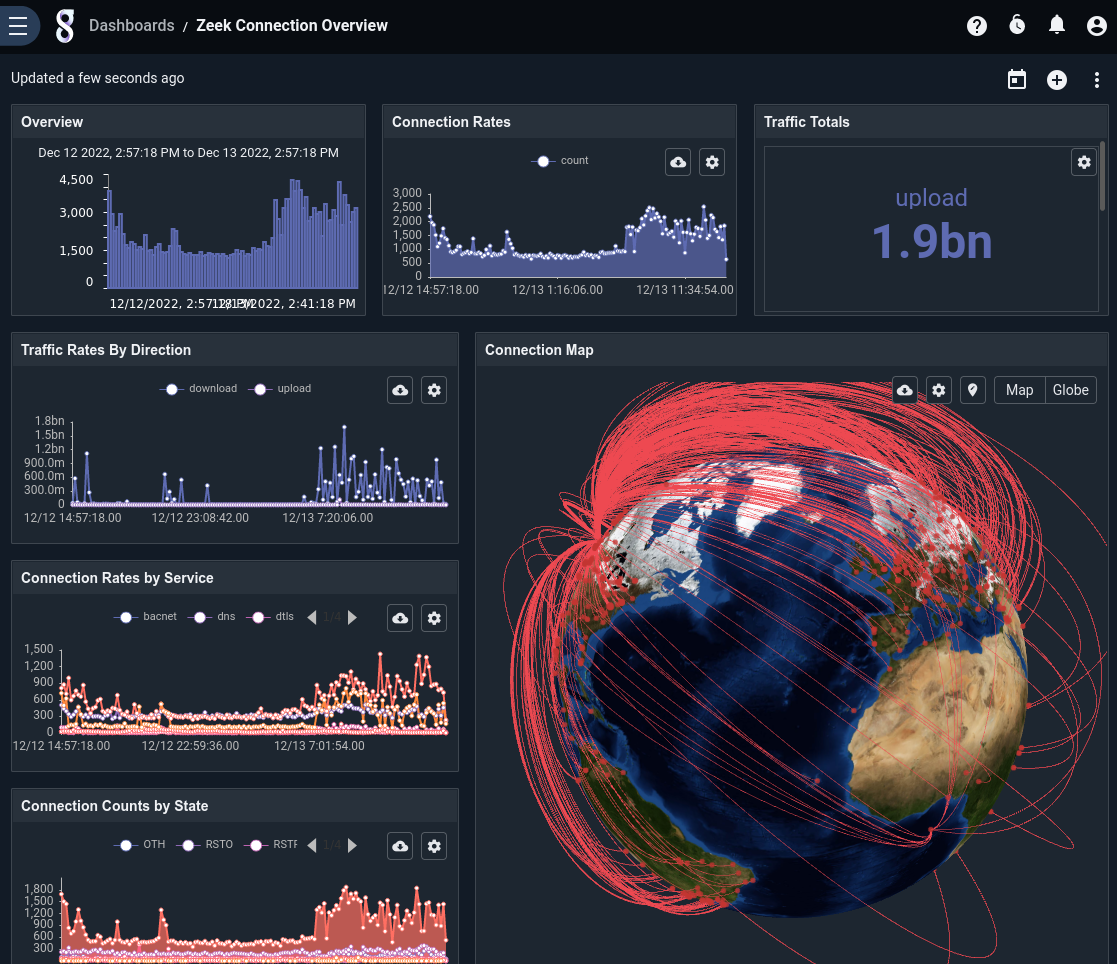
We can use the Overview tile to investigate particular spans of time by clicking and dragging the mouse to “sweep” a portion of time. By default, zooming in on one overview will zoom in on any other searches that are attached to this dashboard.
Installing Kits#
Gravwell Kits are pre-packaged tool sets for analyzing a particular data source. Kits exist to analyze Netflow v5, IPFIX, CoreDNS, and more. They’re a great way to get started with your data, a jumping-off place to building your own analysis.
Most kits rely on you to set up ingesters (e.g. the Netflow v5 kit expects that you’re running the Netflow ingester to gather Netflow records), but the Weather kit is actually entirely self-contained. It includes a script which will run every minute and fetch weather data for locations you specify.
Note
To use the Weather kit, you’ll need an API key from openweathermap.org. The instructions to get an API key can be found here.
You can find the kit by clicking the “Kits” item in the main menu. If there are no kits already installed, the GUI will automatically show you a list of available kits:
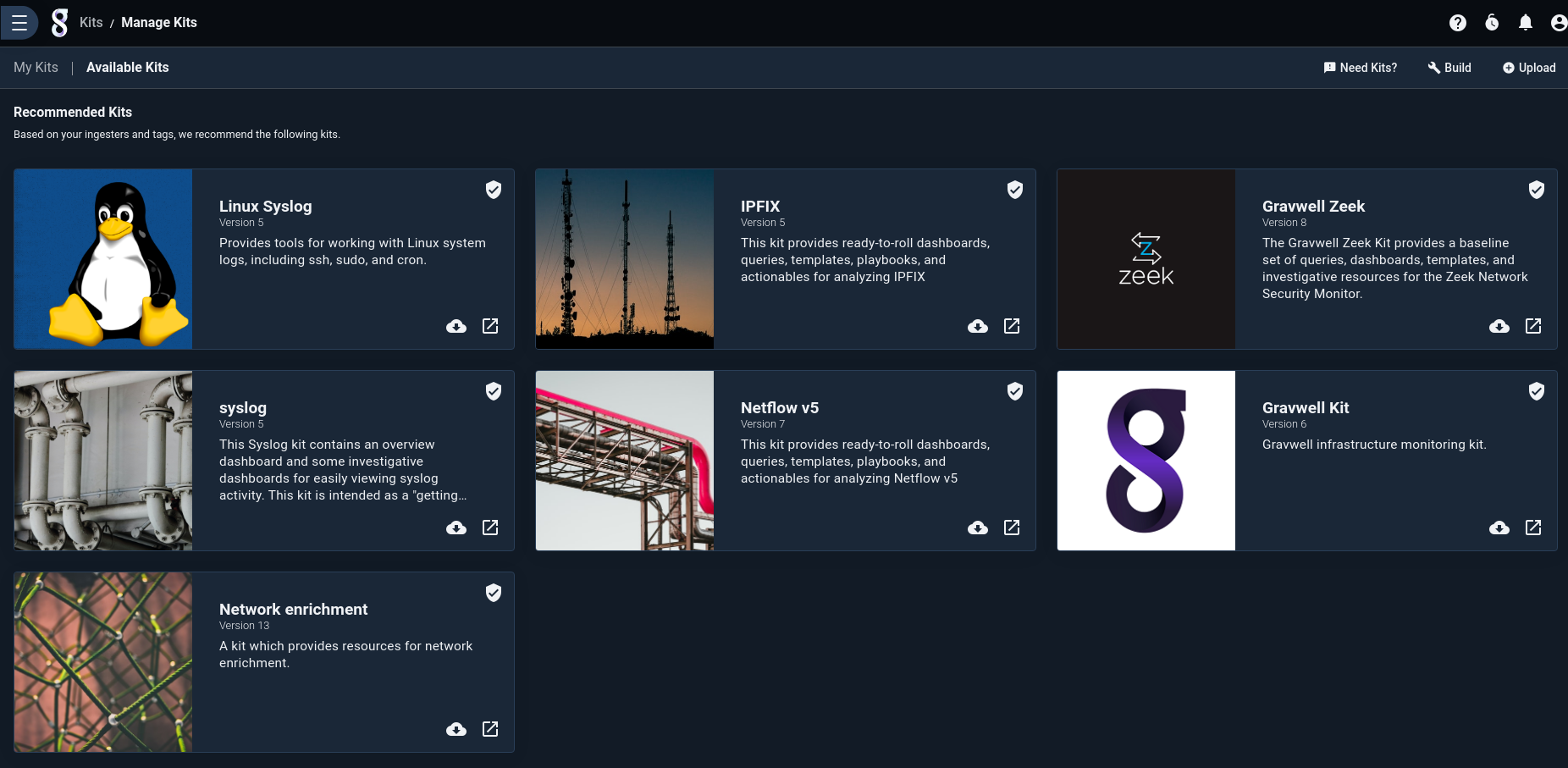
We want to install the Weather kit, so click the deploy icon (an arrow pointing out of a box) on the Weather kit’s tile. This will bring up the installation wizard. The first page lists the items included in the kit and provides an opportunity to review the contents; select the checkbox at the bottom, then hit Next:

The second page contains Configuration Macros. These are used to configure the kit. You’ll need to enter your OpenWeatherMap API key in the first macro, then set a list of locations to monitor in the second. The third macro controls the units used and can be left at the default (“imperial”) or changed to “metric”. When entering values in the configuration macro fields, first click the “Enter custom value” link to turn off certain validation rules.
Note
The list of locations should consist of a colon-separated list of locations as described in this document. Note that multiple countries use the same ZIP code format as the US, so specifying “87110,us” is usually better than just “87110”.
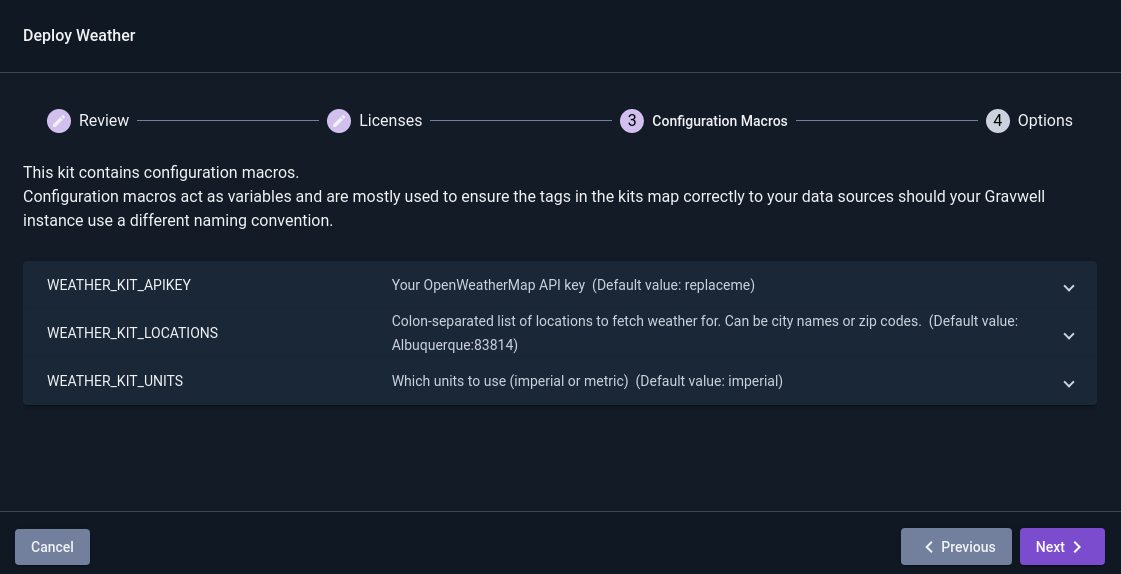
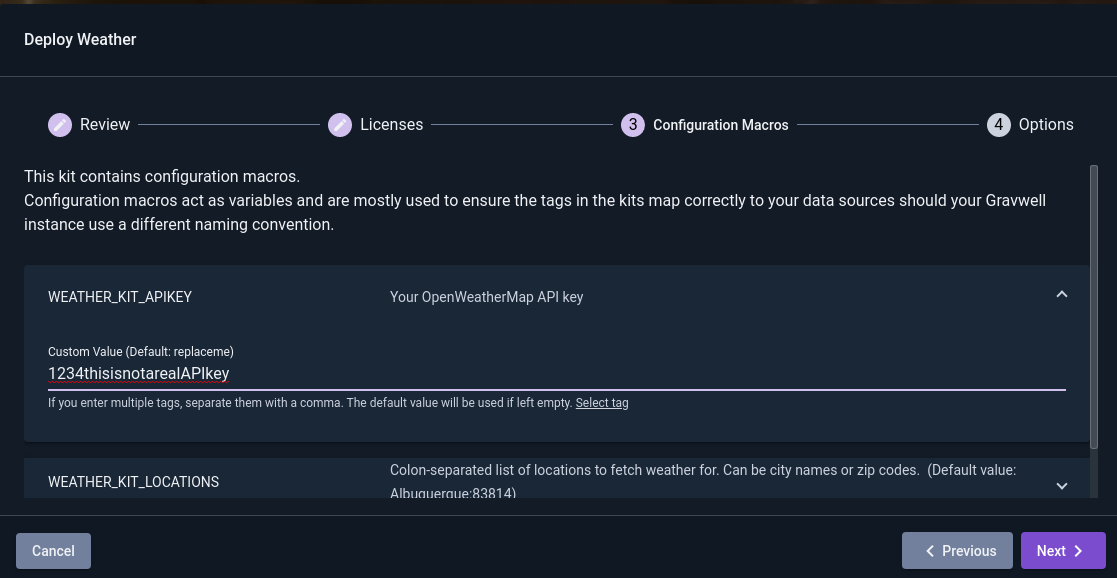
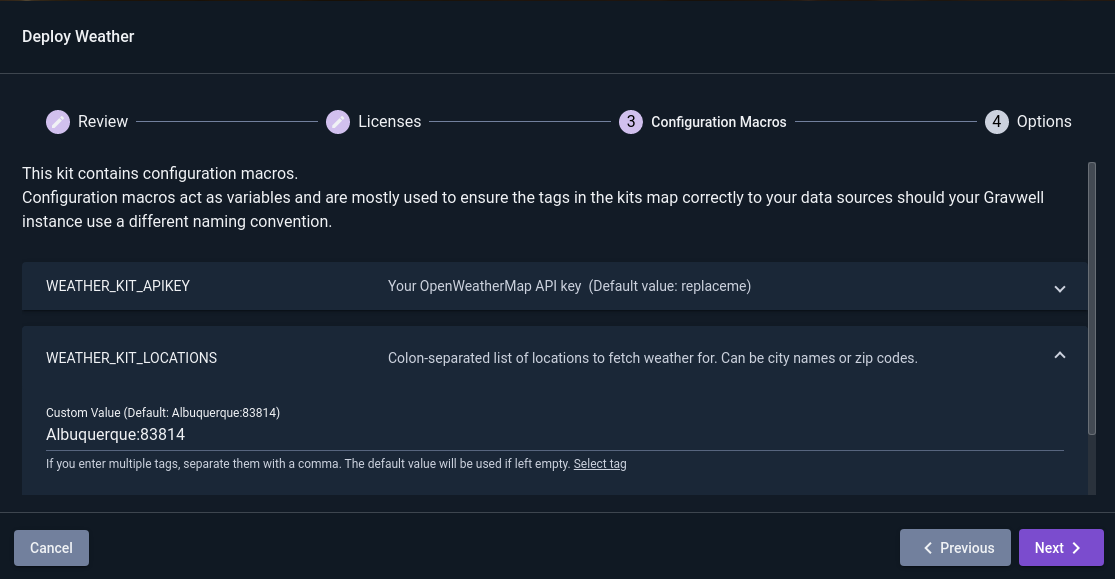
When you are done setting up Config Macros, click “Next” for the final page of the wizard. This gives a few final options relating to the kit installation; you can simply click “Deploy”:
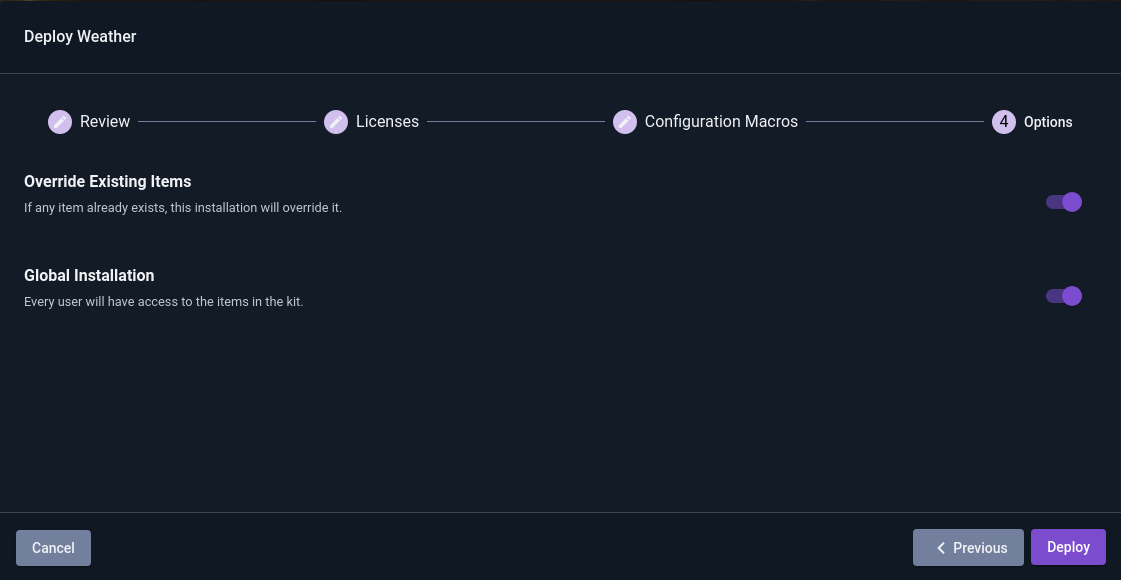
Once the kit is installed, you will be taken to a list of installed kits, which should show the newly-installed Weather kit:
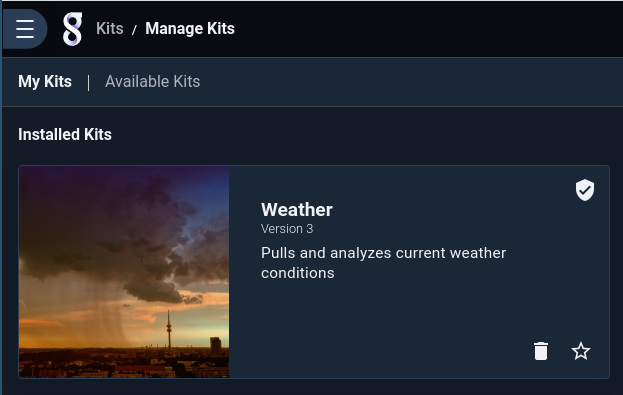
The script included in the kit should soon begin pulling in weather data. After a minute or two, we should have some data to work with, so click the main menu, open the “Dashboards” page, and click the “Weather Overview” dashboard. There won’t be much to see on the temperature charts yet, but you should at least be able to look at the “Current Conditions” table in the lower left:
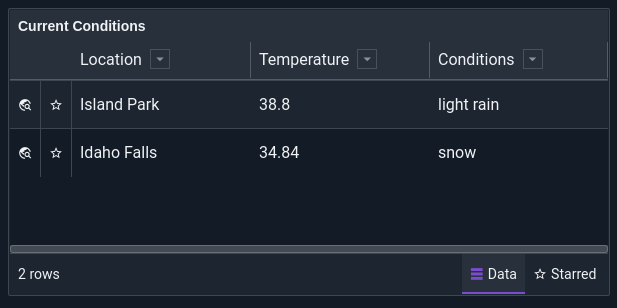
After a day or so, you’ll have gathered enough data to see nice charts like this:
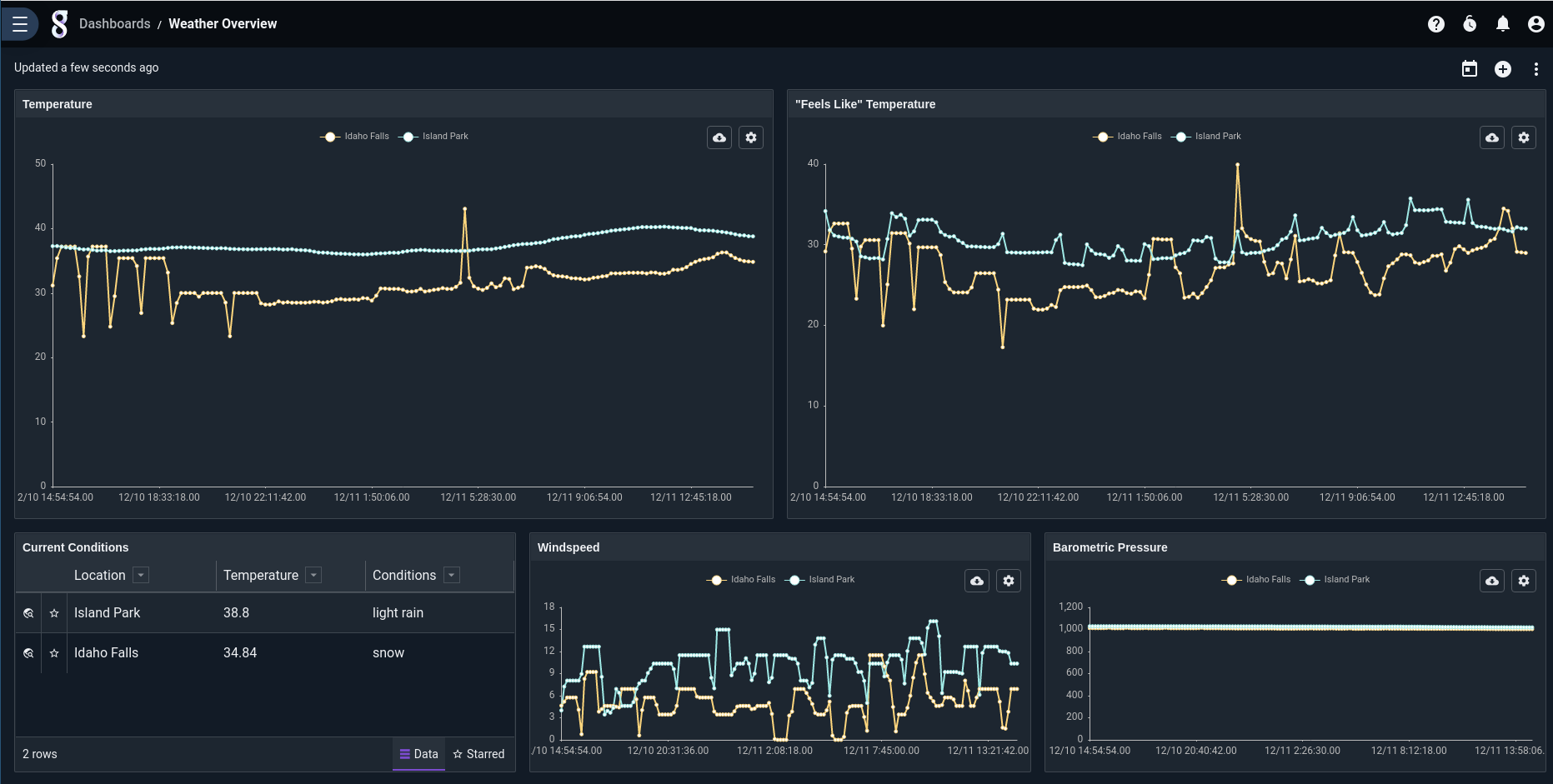
Refer to the kits documentation for more details on Gravwell Kits.
Updating Gravwell#
Upgrading Gravwell is an uneventful affair, we take great pains to ensure that the installation and upgrade process is fast and easy. The upgrade process is different depending on your original installation method. If you are using one of the package repositories, such as Debian, Gravwell is upgraded like any other application:
apt update
apt upgrade
If your original installation method was the self-contained shell installer, you simply download and run the latest version of the installer. The self-contained installers act as both installation and upgrade systems, they will detect an existing installation and skip over any steps that do not apply to an upgrade.
Upgrade Tips#
There are a few tips to upgrading that can help in some installations.
Cluster configurations should cascade indexer upgrades so that ingesters can continue normal operation during the upgrade
The same is true for distributed webserver configurations, the load balancer will shift users as needed
If possible, time upgrades to the search agent when there are no large automated script jobs running
Distribution package managers will sometimes prompt about upstream configuration file changes, but make sure to keep your existing configs
It’s ok to check what changed, we are usually just adding configurations for new features
If you accept upstream configuration files it may overwrite your configurations and cause components failures
After an upgrade it is always a good practice to check the state of Gravwell by ensuring that all indexers are present and accounted for and that ingesters have reconnected and are reporting the expected version numbers.
Advanced Topics#
Crash Reporting and Metrics#
The Gravwell software has automated crash reporting & metrics reporting built in. For more information about what gets sent back to us at Gravwell, see the crash reporting and metrics page.
Clustered Configurations#
Users with multi-node licenses can deploy multiple indexer and webserver instances and coordinate them over the network. We highly recommend coordinating with Gravwell’s support team before deploying such a setup, but will outline the basic steps in this document.
For most use cases, a single webserver and multiple indexer nodes will be desirable. For simplicity, we will describe an environment in which the webserver resides on the same node as one of the indexers.
First, perform a single-node Gravwell installation as described above on the system which will be the head node. This will install the webserver and indexer and generate authentication secrets:
root@headnode# bash gravwell_installer.sh
Next, make a copy of /opt/gravwell/etc/gravwell.conf somewhere else and remove any lines beginning with ‘Indexer-UUID’. Copy this gravwell.conf file and the installer to each of the indexer nodes. On the indexer nodes, we pass additional arguments to the installer to disable installation of the webserver and to specify that the existing gravwell.conf file should be used rather than generating a new one:
root@indexer0# bash gravwell_installer.sh --no-webserver --no-searchagent --use-config /root/gravwell.conf
Repeat this process for each indexer node.
The final step of the installation is to inform the webserver of all these indexers. On the head node, open /opt/gravwell/etc/gravwell.conf and find the ‘Remote-Indexers’ line. It should look something like Remote-Indexers=net:127.0.0.1:9404. Now duplicate that line and modify the IPs to point at the other indexers (you can specify IP addresses or hostnames). For example, if there is an indexer on the local machine and on 3 other machines named indexer0.example.net, indexer1.example.net, and indexer2.example.net, the config file should contain these lines:
Remote-Indexers=net:127.0.0.1:9404
Remote-Indexers=net:indexer0.example.net:9404
Remote-Indexers=net:indexer1.example.net:9404
Remote-Indexers=net:indexer2.example.net:9404
Restart the webserver with the command systemctl restart gravwell_webserver. Now, when you view the “Systems Stats” page and click on the “Hardware” tab, you should see entries for each of the 4 indexer processes.
Uninstalling Gravwell#
If you decide you no longer want Gravwell installed on a particular system, the removal process is relatively straightforward.
On Redhat and Debian systems, uninstalling the package should disable the services and remove the Gravwell binaries. It is then your choice to remove the rest of /opt/gravwell; note that if you delete the storage directories, any data that was ingested into your Gravwell system will be lost!
Debian:
apt-get remove gravwell gravwell-crash-reporterRedhat:
yum remove gravwell gravwell-crash-reporter
On Docker systems, use docker kill and docker rm to remove your Gravwell container. You may need to delete any persistent volumes you created.
Newer versions of the self-contained shell installer have a --uninstall flag, which disables the gravwell_webserver, gravwell_indexer, gravwell_searchagent, and gravwell_crash_reporter services but does not actually delete any data. You can also manually disable those services, then delete /opt/gravwell if desired.