
Ingesters#
This section contains more detailed instruction for configuring and running Gravwell ingesters, which gather incoming data, package it into Gravwell entries, and ship it to Gravwell indexers for storage. The ingesters described in these pages are primarily designed to capture live data as it is generated; if you have existing data you want to import, check out the migration documents.
The Gravwell-created ingesters are released under the BSD open source license and can be found on Github. The ingest API is also open source, so you can create your own ingesters for unique data sources, performing additional normalization or pre-processing, or any other manner of things. The ingest API code is located here.
In general, for an ingester to send data to Gravwell, the ingester will need to know the “Ingest Secret” of the Gravwell instance, for authentication. This can be found by viewing the /opt/gravwell/etc/gravwell.conf file on the Gravwell server and finding the entry for Ingest-Auth. If the ingester is running on the same system as Gravwell itself, the installer will usually be able to detect this value and set it automatically.
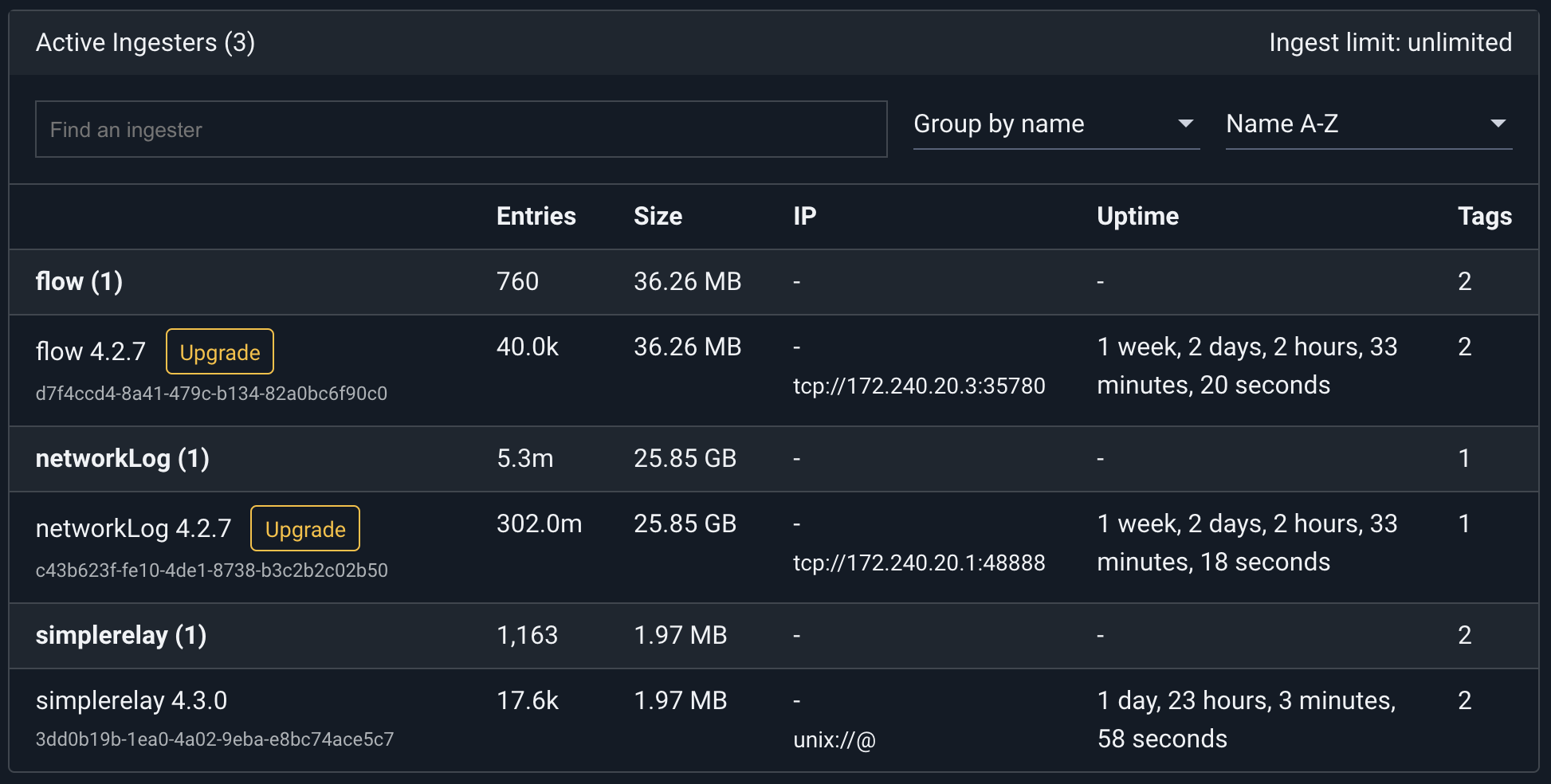
The Gravwell GUI has an Ingesters page (under the System menu category) which can be used to easily identify which remote ingesters are actively connected, for how long they have been connected, and how much data they have pushed.
Attention
The replication system does not replicate entries larger than 999MB. Larger entries can still be ingested and searched as usual, but they are omitted from replication. This is not a concern for 99.9% of use cases, as all the ingesters detailed in this page tend to create entries no larger than a few kilobytes.
Ingesters List#
Ingester |
Description |
|---|---|
Subscribe and ingest from Amazon SQS queues. |
|
Consume from Azure Event Hubs. |
|
Ingest collectd samples. |
|
Watch and ingest files on disk, such as logs. |
|
Fetch and ingest entries from Google Compute Platform PubSub Streams. |
|
Create HTTP listeners on multiple URL paths. |
|
Periodically collect SDR and SEL records from IPMI devices. |
|
Create a Kafka Consumer that ingests into Gravwell. Can be paired with the Gravwell Kafka Federator. |
|
Ingest from Amazon’s Kinesis Data Streams service. |
|
Ingest from Microsoft’s Graph API. |
|
Collect Netflow and IPFIX records. |
|
Ingest PCAP on the wire. |
|
Ingest Microsoft o365 Logs. |
|
Issue queries and ingest data from Google Stenographer. |
|
Ingest data directly from Amazon S3 buckets, including Cloudtrail logs. |
|
Ingest large records into a single entry. |
|
Ingest Shodan streaming API events. |
|
Ingest any text over TCP/UDP, syslog, and more. |
|
Receive and ingest SNMP trap messages. |
|
Collect Windows events. |
|
Watch and ingest files on Windows, such as logs and EVTX files. |
Hosted Ingesters#
Hosted ingesters run inside the Gravwell Hosted Runner, reducing the amount of infrastructure needed to run the lighter-weight, non-streaming ingesters.
Ingester |
Description |
|---|---|
Ingest Mimecast MTA SIEM and audit events. |
|
Ingest Okta system logs and user records. |
Global Configuration Parameters#
Most of the core ingesters support a common set of global configuration parameters. The shared Global configuration parameters are implemented using the ingest config package. Global configuration parameters should be specified in the Global section of each Gravwell ingester config file. The following Global ingester parameters are available:
Ingest-Secret#
The Ingest-Secret parameter specifies the token to be used for ingest authentication. The token specified here MUST match the Ingest-Auth parameter for Gravwell indexers.
Ingest-Secret-File#
There may be instances where it is undesirable to load ingest secrets as cleartext strings directly from a configuration file; the Ingest-Secret-File parameter can be used to specify a file containing the Ingest-Secret. The Ingest-Secret-File should contain the full path to a file containing only the secret value. The file must be readable by the calling ingester. If both Ingest-Secret and Ingest-Secret-File are specified, the Ingest-Secret value takes precedence; if the Ingest-Secret is populated via an environment variable, Ingest-Secret-File is ignored.
See the page on Environment Variables for additional methods to divorce secrets from config files.
Connection-Timeout#
The Connection-Timeout parameter specifies how long we want to wait to connect to an indexer before giving up. An empty timeout means that the ingester will wait forever to start. Timeouts should be specified in duration of minutes, seconds, or hours.
Examples#
Connection-Timeout=30s
Connection-Timeout=5m
Connection-Timeout=1h
Insecure-Skip-TLS-Verify#
The Insecure-Skip-TLS-Verify token tells the ingester to ignore bad certificates when connecting over encrypted TLS tunnels. As the name suggests, any and all authentication provided by TLS is thrown out the window and attackers can easily Man-in-the-Middle TLS connections. The ingest connections will still be encrypted, but the connection is by no means secure. By default TLS certificates are validated and the connections will fail if the certificate validation fails.
Examples#
Insecure-Skip-TLS-Verify=true
Insecure-Skip-TLS-Verify=false
Rate-Limit#
The Rate-Limit parameter sets a maximum bandwidth which the ingester can consume. This can be useful when configuring a “bursty” ingester that talks to the indexer over a slow connection, so the ingester doesn’t hog all the available bandwidth when it is trying to send a lot of data.
The argument should be a number followed by an optional rate suffix, e.g. 1048576 or 10Mbit. The following suffixes exist:
kbit, kbps, Kbit, Kbps: “kilobits per second”
KBps: “kilobytes per second”
mbit, mbps, Mbit, Mbps: “megabits per second”
MBps: “megabytes per second”
gbit, gbps, Gbit, Gbps: “gigabits per second”
GBps: “gigabytes per second”
Examples#
Rate-Limit=1Mbit
Rate-Limit=2048Kbps
Rate-Limit=3MBps
Enable-Compression#
The ingest system supports a transparent compression system that will compress data as it flows between ingesters and indexers. This transparent compression is extremely fast and can help reduce load on slower links. Each ingester can request a compressed uplink for all connections by setting the Enable-Compression parameter to true in the global configuration block.
The compression system is opportunistic in that the ingester requests compression but the upstream link gets the final say on whether compression is enabled; if the upstream endpoint does not support compression or has been configured to disallow it the link will not be compressed.
Compression will increase the CPU and memory requirements of an ingester, if the ingester is running on an endpoint with minimal CPU and/or memory compression may reduce throughput. Compression is best suited for WAN connections, enabling compression on a Unix named pipe just incurs CPU and memory overhead with no added benefit.
Example#
Enable-Compression=true
Cleartext-Backend-Target#
Cleartext-Backend-Target specifies the host and port of a Gravwell indexer. The ingester will connect to the indexer using a cleartext TCP connection. If no port is specified the default port 4023 is used. Cleartext connections support both IPv6 and IPv4 destinations. Multiple Cleartext-Backend-Targets can be specified to load balance an ingester across multiple indexers.
Examples#
Cleartext-Backend-Target=192.168.1.1
Cleartext-Backend-Target=192.168.1.1:4023
Cleartext-Backend-Target=DEAD::BEEF
Cleartext-Backend-Target=[DEAD::BEEF]:4023
Encrypted-Backend-Target#
Encrypted-Backend-Target specifies the host and port of a Gravwell indexer. The ingester will connect to the indexer via TCP and perform a full TLS handshake/certificate validation. If no port is specified the default port of 4024 is used. Encrypted connections support both IPv6 and IPv4 destinations. Multiple Encrypted-Backend-Targets can be specified to load balance an ingester across multiple indexers.
Examples#
Encrypted-Backend-Target=192.168.1.1
Encrypted-Backend-Target=192.168.1.1:4023
Encrypted-Backend-Target=DEAD::BEEF
Encrypted-Backend-Target=[DEAD::BEEF]:4023
Pipe-Backend-Target#
Pipe-Backend-Target specifies a Unix named socket via a full path. Unix named sockets are ideal for ingesters that are co-resident with indexers as they are extremely fast and incur little overhead. Only a single Pipe-Backend-Target is supported per ingester, but pipes can be multiplexed alongside cleartext and encrypted connections.
Examples#
Pipe-Backend-Target=/opt/gravwell/comms/pipe
Pipe-Backend-Target=/tmp/gravwellpipe
Ingest-Cache-Path#
The Ingest-Cache-Path enables a local cache for ingested data. When enabled, ingesters can cache locally when they cannot forward entries to indexers. The ingest cache can help ensure you don’t lose data when links go down or if you need to take a Gravwell cluster offline momentarily. Be sure to specify a Max-Ingest-Cache value so that a long-term network failure won’t cause an ingester to fill the host disk. The local ingest cache is not as fast as ingesting directly to indexers, so don’t expect the ingest cache to handle 2 million entries per second the way the indexers can.
Attention
The ingest cache should not be enabled for the File Follower ingester. Because this ingester reads directly from files on the disk and tracks its position within each file, it does not need a cache.
Examples#
Ingest-Cache-Path=/opt/gravwell/cache/simplerelay.cache
Ingest-Cache-Path=/mnt/storage/networklog.cache
Max-Ingest-Cache#
Max-Ingest-Cache limits the amount of storage space an ingester will consume when the cache is engaged. The maximum cache value is specified in megabytes; a value of 1024 means that the ingester can consume 1GB of storage before it will stop accepting new entries. The cache system will NOT overwrite old entries when the cache fills up. This is by design, so that an attacker can’t disrupt a network connection and cause an ingester to overwrite potentially critical data at the point the disruption happened.
Examples#
Max-Ingest-Cache=32
Max-Ingest-Cache=1024
Max-Ingest-Cache=10240
Cache-Depth#
Cache-Depth sets the number of entries to keep in an in-memory buffer. The default value is 128, and the in-memory buffer is always enabled, even if Ingest-Cache-Path is disabled. Setting Cache-Depth to a large value enables absorbing burst behavior on ingesters as the expense of more memory consumption.
Example#
Cache-Depth=256
Cache-Mode#
Cache-Mode sets the behavior of the backing cache (enabled by setting Ingest-Cache-Path) at runtime. Available modes are “always” and “fail”. In “always” mode, the cache is always enabled, allowing the ingester to write entries to disk any time the in-memory buffer (set with Cache-Depth) is full. This can occur on a dead or slow indexer connection, or when the ingester is attempting to push more data than is possible over the connection it has to the indexer. By using “always” mode, you ensure the ingester will not drop entries or block data ingest at any time. Setting Cache-Mode to “fail” changes the cache behavior to only enable when all indexer connections are down.
Examples#
Cache-Mode=always
Cache-Mode=fail
Log-File#
Ingesters can log errors and debug information to log files to assist in debugging installation and configuration problems. An empty Log-File parameter disables file logging.
Examples#
Log-File=/opt/gravwell/log/ingester.log
Log-Level#
The Log-Level parameter controls the logging system in each ingester for both log files and metadata that is sent to indexers under the “gravwell” tag. Setting the log level to INFO will tell the ingester to log in great detail, such as when the File Follower follows a new file or Simple Relay receives a new TCP connection. On the other end of the spectrum, setting the level to ERROR means only the most critical errors will be logged. The WARN level is appropriate in most cases. The following levels are supported:
OFF
INFO
WARN
ERROR
Examples#
Log-Level=Off
Log-Level=INFO
Log-Level=WARN
Log-Level=ERROR
Source-Override#
The Source-Override parameter will override the SRC data item that is attached to each entry. The SRC item is either an IPv6 or IPv4 address and is normally the external IP address of the machine on which the ingester is running.
Examples#
Source-Override=10.0.0.1
Source-Override=0.0.0.0
Source-Override=DEAD:BEEF::FEED:FEBE
Log-Source-Override#
Many ingesters can emit entries on the gravwell tag for the purposes of auditing, health and status, and general ingest infrastructure logging. Typically, these entries will use the source IP address of the ingester as seen from the indexer for the SRC field. However, it can be useful to override the source IP field for only the entries that are actually generated by the ingester. A good example would be using the Log-Source-Override on the Gravwell Federator to change the SRC field for health and status entries, but not every entry that transits the Federator.
The Log-Source-Override configuration parameter requires an IPv4 or IPv6 value as a parameter.
Examples#
Log-Source-Override=10.0.0.1
Log-Source-Override=0.0.0.0
Log-Source-Override=DEAD:BEEF::FEED:FEBE
Log-Source-Override=::1
Note
Log-Source-Override should not be confused with Source-Override. Source-Override changes the source value for logs that are gathered by the ingesters from data sources (files, remote APIs, remote connections, etc.), while Log-Source-Override changes the source value for logs that are generated by the ingester and sent to the gravwell tag. For example, setting Source-Override for the IPMI ingester will override the SRC value for all IMPI entries where setting the Log-Source-Override will override the SRC value for the status, info, and error logs emitted into the gravwell tag by the IMPI ingester while leaving the SRC value intact for all IMPI events.
Attach#
All ingesters support the Attach global configuration stanza, which allows intrinsic enumerated values to be attached to entries during ingest. Intrinsic enumerated values can later be accessed with the intrinsic search module.
The Attach stanza takes any key/value pair, and will attach it to every entry as an enumerated value at the time of ingest. For example:
[Attach]
foo = "bar"
ingester = "my ingester"
Will attach an EV “foo” with the contents “bar” to every entry, as well as “ingester” with the value “my ingester”.
Additionally, dynamic values can be attached which are resolved from the host environment. Dynamic values begin with a $ character. There are 3 special dynamic values which are not resolved from environment variables: $NOW, $HOSTNAME, $UUID. If an environment variable cannot be found, the below variables can be used to populate values:
[Attach]
time = $NOW # add the current timestamp
host = $HOSTNAME # add the hostname the ingester is running on
uuid = $UUID # add the ingester's UUID
home = $HOME # add the environment variable "HOME"
Max-Entry-Size#
The Max-Entry-Size parameter will limit the maximum size of entries coming into the system. By default this is set to ~1GB. The value is specified in bytes. When exceeded, the entry will be dropped and a log will be written noting the max size was exceeded.
Setting this too low can result in data loss.
Warning
This is one of the few configuration options that will entirely drop entries. Extreme care should be taken to analyze incoming data before adjusting this.
You can use a query like tag=default | length | sort by length desc | table length, DATA to see the entries sorted by size.
When modifying this, it is best to check that no entries are being dropped once the ingester is running. The below query can be used as a starting point for finding instances of dropped entries.
tag=gravwell syslog error~"Entry data exceeds maximum size"
Data Consumer Configuration#
Besides the global configuration options, each ingester which uses a config file will need to define at least one data consumer. A data consumer is a config definition which tells the ingester:
Where to get data
What tag to use on the data
Any special timestamp processing rules
Overrides for fields such as the SRC field
The Simple Relay ingester and the HTTP ingester define “Listeners”; File Follow uses “Followers”; the netflow ingester defines “Collectors”. The individual ingester sections below describe the ingester’s particular data consumer types and any unique configurations they may require. The following example shows how the File Follower ingester defines a “Follower” data consumer to read data from a particular directory:
[Follower "syslog"]
Base-Directory="/var/log/"
File-Filter="syslog,syslog.[0-9]" #we are looking for all authorization log files
Tag-Name=syslog
Assume-Local-Timezone=true #Default for assume localtime is false
Note how it specifies the data source (via the Base-Directory and File-Filter rules), which tag to use (via Tag-Name), and an additional rule for parsing timestamps in the incoming data (Assume-Local-Timezone).
Time#
Timestamp Extraction#
All ingesters attach a timestamp to each entry sent to an indexer. Most ingesters extract timestamps from the data being ingested, such as the timestamp field in Syslog, and ingesters will extract timestamps as appropriate to the data. When an ingester cannot extract a timestamp, or the input data does not have a timestamp at a known position in the input data, the ingester will attempt to find a timestamp using a number of formats.
If the ingester still cannot find a valid timestamp, the current time will be applied to the entry.
When an ingester attempts to find a timestamp based on the list of timestamp formats, it will always try the last successful format first. For example, if an entry has a timestamp 02 Jan 06 15:04 MST, the ingester will attempt to parse the next entry with the same timestamp format. If it does not match, then the ingester will attempt all other timestamp formats.
There are several ways to change the behavior of how timestamps are parsed, detailed in the next section. Additionally, fully custom timestamp formats can be provided in some ingesters.
Below is the list of time formats that will be searched.
Timestamp Name |
Example |
|---|---|
AnsiCFormat |
|
UnixFormat |
|
RubyFormat |
|
RFC822Format |
|
RFC822ZFormat |
|
RFC850Format |
|
RFC1123Format |
|
RFC1123ZFormat |
|
RFC3339Format |
|
RFC3339NanoFormat |
|
ZonelessRFC3339Format |
|
ApacheFormat |
|
ApacheNoTzFormat |
|
NGINXFormat |
|
SyslogFormat |
|
SyslogFileFormat |
|
SyslogFileTZFormat |
|
DPKGFormat |
|
SyslogVariantFormat |
|
UnpaddedDateTimeFormat |
|
UnpaddedMilliDateTimeFormat |
|
UnixSecondsFormat |
|
UnixMilliFormat |
|
UnixMsFormat |
|
UnixNanoFormat |
|
LDAPFormat |
|
UKFormat |
|
GravwellFormat |
|
BindFormat |
|
DirectAdminFormat |
|
Time Zones#
Dealing with time zones can be one of the most challenging and frustrating aspects of ingestion. If a log’s timestamp includes an explicit UTC offset (e.g. “-0700”), things are relatively easy, but many log formats do not include any time zone information at all! Sometimes, the system generating the log entry is in a local time zone, while the Gravwell ingester’s system is set to UTC, or vice versa.
If you believe you have configured your ingester properly, but you’re not seeing any data in a query, try expanding your query timeframe to include the future using the “Date Range” timeframe selection: just set the End Date to some time tomorrow. If the Gravwell ingest system is set to a US time zone, but the logs are in UTC time with no offset included, the incoming data will be ingested in the “future”.
The Timezone-Override parameter (described below) is the surest way to fix time zone problems. If your data has a UTC timestamp but the system clock is set to another time zone, set Timezone-Override="Etc/UTC". If your data is in US Eastern time, but the system clock is set to UTC, set Timezone-Override="America/New_York", and so on.
Time Parsing Overrides#
Most ingesters attempt to apply a timestamp to each entry by extracting a timestamp from the data. There are several options which can be applied to each data consumer for fine-tuning of this timestamp extraction:
Ignore-Timestamps(boolean): settingIgnore-Timestamps=truewill make the ingester apply the current time to each entry rather than attempting to extract a timestamp. This can be the only option for ingesting data when you have extremely incoherent incoming data.Assume-Local-Timezone(boolean): By default, if a timestamp does not include a time zone the ingester will assume it is a UTC timestamp. SettingAssume-Local-Timezone=truewill make the ingester instead assume whatever the local computer’s timezone is. This is mutually exclusive with the Timezone-Override option.Timezone-Override(string): SettingTimezone-Overridetells the ingester that timestamps which don’t include a timezone should be parsed in the specified timezone. ThusTimezone-Override=US/Pacificwould tell the ingester to treat incoming timestamps as if they were in US Pacific time. See this page for a complete list of acceptable timezone names (in the ‘TZ database name’ column). Mutually exclusive with Assume-Local-Timezone.Timestamp-Format-Override(string): This parameter tells the ingester to look for a specific timestamp format in the data, e.g.Timestamp-Format-Override="RFC822". Refer to the timegrinder documentation for a full list of possible overrides, with examples.Timestamp-Max-Past-Delta,Timestamp-Max-Future-Delta(string): If set to a valid duration (e.g. “24h”), defines a maximum duration into the past or future for timestamps parsed by timegrinder. Timestamps outside that window are ignored; timegrinder will attempt to find another valid timestamp within the allowable window, otherwise the entry will receive the current timestamp. This can be particularly useful when entries contain multiple timestamps in the same format and the “wrong” one can appear first, e.g.{"CreationTime": "2019-03-01T12:34:56Z", "EventTime": "2025-02-20T11:10:22Z"}.
The Kinesis and Google Pub/Sub ingesters do not provide the Ignore-Timestamps option. Kinesis and Pub/Sub include an arrival timestamp with every entry; by default, the ingesters will use that as the Gravwell timestamp. If Parse-Time=true is specified in the data consumer definition, the ingester will instead attempt to extract a timestamp from the message body. See these ingesters’ respective sections for additional information.
Custom timestamp formats are supported on many ingesters, see Custom Time Formats for more information.
Source-Override#
The “Source-Override” parameter instructs the consumer to ignore the source of the data and apply a hard coded value. It may be desirable to hard code source values for incoming data as a method to organize and/or group data sources. “Source-Override” values can be IPv4 or IPv6 values.
Source-Override=192.168.1.1
Source-Override=127.0.0.1
Source-Override=[fe80::899:b3ff:feb7:2dc6]
Label#
The Label parameter allows for attaching an arbitrary string that will be sent upstream and displayed in the Systems & Health page for ingesters. Attaching a Label to an ingester can be a helpful way to organize and/or tag ingesters with useful information.
Label="Bob's personal ingester"
Ingest API#
The Gravwell ingest API and core ingesters are fully open source under the BSD 2-Clause license. This means that you can write your own ingesters and integrate Gravwell entry generation into your own products and services. The core ingest API is written in Go, but the list of available API languages is under active expansion.
A very basic ingester example (less than 100 lines of code) that watches a file and sends any lines written to it up to a Gravwell cluster can be seen here
Keep checking back with the Gravwell GitHub page, as the team is continually improving the ingest API and porting it to additional languages. Community development is fully supported, so if you have a merge request, language port, or a great new ingester that you have open sourced, let Gravwell know! The Gravwell team would love to feature your hard work in the ingester highlight series.
Starting the Same Ingester Multiple Times with Systemd#
There are use cases where you may need to instantiate multiple copies of the same ingester with different configurations. For example, you may need to have two simple-relay ingesters running on the same machine, but with different global configurations. Systemd simplifies this through the use of service templates.
Below is an example service template for simple-relay that allows specifying the configuration file and enabling multiple copies of the simple-relay service.
The below file requires an ‘@’ at the end of the filename. We’ll name this file /etc/systemd/system/gravwell_simple_relay@.service
[Install]
WantedBy=multi-user.target
[Unit]
Description=Gravwell Log Relay Service, Config: %i
After=network-online.target
OnFailure=gravwell_crash_reporter@%n.service
[Service]
Type=simple
ExecStart=/opt/gravwell/bin/gravwell_simple_relay -stderr %n -config-file %i
ExecStopPost=/opt/gravwell/bin/gravwell_crash_reporter -exit-check %n
WorkingDirectory=/opt/gravwell
Restart=always
User=gravwell
Group=gravwell
StandardOutput=null
StandardError=journal
LimitNPROC=infinity
LimitNOFILE=infinity
TimeoutStopSec=5
KillMode=process
KillSignal=SIGINT
Note the use of %i in the service file. This allows us to use variable substitution when enabling this service file. We can enable it as many times as needed by specifying the config file in the “name” of the service file:
sudo systemctl enable gravwell_simple_relay@/opt/gravwell/etc/config1.conf
sudo systemctl enable gravwell_simple_relay@/opt/gravwell/etc/config2.conf
This will create two instances of the service defined above, each with a different config file, as specified in the commands above. Additionally, the use of “enable” in the commands above will cause these instantiations to persist across reboots and start at boot time.
Non-interactive installation of Gravwell Ingesters#
It is possible to install ingesters in non-interactive mode. This is useful for batch deployment. When installing using non-interactive modes, the installer will attempt to use certain configuration options, such as indexer authentication keys, if they can be detected from an existing indexer configuration file. Otherwise, the installation will leave a default configuration, requiring the user to make modifications before starting the ingester.
Debian#
To install packages in non-interactive mode on Debian, use the DEBIAN_FRONTEND environment variable when using apt or apt-get. For example, to install Simple Relay:
DEBIAN_FRONTEND=noninteractive apt-get -y install gravwell-simple-relay
Redhat#
Gravwell packages for Redhat are already non-interactive. To additionally answer “yes” to yum prompting to install dependencies, you can use the -y flag:
yum -y install gravwell-simple-relay
Windows#
Gravwell packages for windows can perform non-interactive installation using standard msiexec flags like /quiet and /i. See the complete documentation on silent installation for more information.
macOS#
To install in non-interactive mode in macOS, you must use the terminal and execute the installer command with root privileges. For example, to install File Follower on macOS:
sudo installer -store -pkg GravwellFileFollower.pkg -target /