
Data Replication#
Replication is included with all Gravwell Cluster Edition licenses, allowing for fault-tolerant high availability deployments. The Gravwell replication engine transparently manages data replication across distributed indexers with automatic failover, load balanced data distribution, and compression. Gravwell also provides fine tuned control over exactly which wells are included in replication and how the data is distributed across peers. Customers can rapidly deploy a Gravwell cluster with uniform data distribution, or design a replication scheme that can tolerate entire data center failures using region-aware peer selection. The online failover system also allows continued access to data even when some indexers are offline.
Attention
Gravwell’s replication system is designed purely to replicate ingested data. It does not back up user accounts, dashboards, search history, resources, etc., which are stored on the webserver rather than the indexers. To add resiliency to a webserver, consider deploying a datastore for your webserver; the datastore will store a redundant live copy of your webserver’s data.
The replication system is logically separated into “Clients” and “Peers”, with each indexer potentially acting as both a peer and a client. A client is responsible for reaching out to known replication peers and driving the replication transactions. When deploying a Gravwell cluster in a replicating mode, it is important that indexers be able to initiate a TCP connection to any peers acting as replication storage nodes.
Replication connections are encrypted by default and require that indexers have functioning X509 certificates. If the certificates are not signed by a valid certificate authority (CA) then Insecure-Skip-TLS-Verify=true must be added to the Replication configuration section.
Replication storage nodes (nodes which receive replicated data) are allotted a specific amount of storage and will not delete data unless the Max-Replicated-Data-GB parameter is set. Even with Max-Replicated-Data-GB set, the replication system will not delete replicated shards until the storage limit has been reached. If a remote client node deletes data as part of normal ageout, the data shard is marked as deleted and prioritized for deletion when the replication node hits its storage limit. The replication system prioritizes deleted shards first, then oldest shards. All replicated data is compressed; if a cold storage location is provided it is usually recommended that the replication storage location have the same storage capacity as the cold and hot storage combined.
Note
By default, the replication engine uses port 9406.
Attention
Entries larger than 999MB will not be replicated. They can be ingested and searched as normal, but are omitted from replication.
Basic Online Deployment#
The most basic replication deployment is a uniform distribution where every Indexer can replicate against every other indexer. A uniform deployment is configured by specifying every other indexer in the Replication Peer fields.

Example Configuration#
Given three indexers (192.168.100.50, 192.168.100.51, 192.168.100.52), the configuration for the indexer at 192.168.100.50 would look like this:
[Replication]
Peer=192.168.100.51
Peer=192.168.100.52
Storage-Location=/opt/gravwell/replication_storage
Insecure-Skip-TLS-Verify=true
Connect-Wait-Timeout=60
Each node specifies the other nodes in its Peer fields.
The replication engine relies on an internal database to maintain the state of the replication system and all peers. If no Database-Path is defined, the system will deploy the database to a file named replication.db within the Storage-Location directory.
Attention
The replication database is critical to the healthy operation of the replication system. It will perform frequent file syncs and often operates in synchronous IO mode. If your replication storage system is slow or employs transparent compression, it is recommended that the replication database be stored on a high IOP storage array. The replication database is typically only a few MB in size, even on very large deployments.
Region Aware Deployment#
The Replication system can be configured to fine tune which peers an indexer is allowed to replicate data to. By controlling replication peers, it is possible to set up availability regions where an entire region can be taken offline without losing data so long as no subsequent losses occur in the online availability zone.
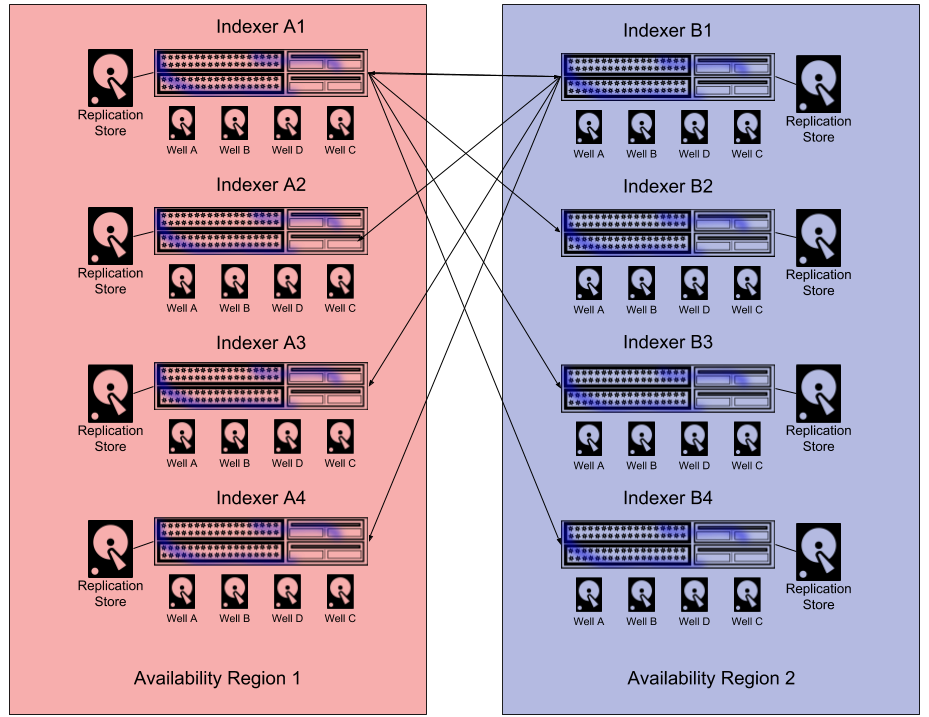
Example Configuration#
An example, an 8 node cluster may be divided into two availability zones (1 and 2). If availability zone 1 had a subnet of 172.16.2.0/24 and availability zone 2 had a subnet of 172.20.1.0/24.
Nodes in Region 1 are configured to replicate to Region 2:
[Replication]
Peer=172.20.1.101
Peer=172.20.1.102
Peer=172.20.1.103
Peer=172.20.1.104
Storage-Location=/opt/gravwell/replication_storage
Connect-Wait-Timeout=60
Nodes in Region 2 are configured to replicate to Region 1:
[Replication]
Peer=172.16.2.101
Peer=172.16.2.102
Peer=172.16.2.103
Peer=172.16.2.104
Storage-Location=/opt/gravwell/replication_storage
Connect-Wait-Timeout=60
You can also use IPv6 addresses for replication peers. For example:
[Replication]
Peer=2001:4860:4860::5555
Storage-Location=/opt/gravwell/replication_storage
Connect-Wait-Timeout=60
Offline Deployment#
Replication is not included with the standard Single Edition Gravwell license. If your organization does not need a multi-node deployment of Gravwell but would like access to the replication engine for managed backups, contact sales@gravwell.io to upgrade a Single Edition license to a replicating Single Edition license. Single edition replication is entirely offline, meaning that if the indexing goes offline the data cannot be searched until the indexer comes back online and completes recovery.

Cluster Edition Gravwell licenses can choose to implement an offline replication configuration using the offline replicator. The offline replicator acts exclusively as a replication peer, and does not provide automatic failover or act as an indexer. Offline replication configurations can be useful in cloud environments where storage systems are already backed by a redundant store and loss is extremely unlikely. By using an offline replication configuration, data can be replicated to a low cost instance that is attached to very low cost storage pools that would not perform well as an indexer. In the unlikely event that an indexer is entirely lost, the low cost replication peer can restore the higher cost indexer instance. Contact sales@gravwell.io for access to the offline replication package.

Configuration Options#
Replication is controlled by the “Replication” configuration group in the gravwell.conf configuration file. The Replication configuration group has the following configuration parameters.
Parameter |
Example |
Description |
|---|---|---|
Peer |
Peer=10.0.0.1:9406 |
Designates a remote system acting as a replication storage node. Multiple Peers can be specified. |
Listen-Address |
Listen-Address=10.0.0.101:9406 |
Designates the address to which the replication system should bind. Default is to listen on all addresses on TCP port 9406. |
Storage-Location |
Storage-Location=/mnt/storage/gravwell/replication |
Designates the full path to use for replication storage. |
Database-Path |
Database-Path=/mnt/storage/gravwell/replication/replication.db |
Optional override to specify the location of the replication DB. If blank, a default name will be used within the |
Max-Replicated-Data-GB |
Max-Replicated-Data-GB=4096 |
Designates the maximum amount of storage the replication system will consume, in this case 4TB. |
Replication-Secret-Override |
Replication-Secret-Override=replicationsecret |
Overrides the authentication token used when establishing connections to replication peers. By default the “Control-Auth” token from the Global configuration group is used. |
Disable-TLS |
Disable-TLS=true |
Disables TLS communication between replication peers. Defaults to false (TLS enabled). |
Insecure-Skip-TLS-Verify |
Insecure-Skip-TLS-Verify=true |
Disables verification and validation of TLS public keys. TLS is still enabled, but the system will accept any public key presented by a peer. |
Key-File |
Key-File=/opt/gravwell/etc/replicationkey.pem |
Overrides the X509 private key used for negotiating a replication connection. By default TLS connections use the Global key file. |
Certificate-File |
Certificate-File=/opt/gravwell/etc/replicationcert.pem |
Overrides the X509 public key certificate used for negotiating a replication connection. By default TLS connections use the Global certificate file. |
Connect-Wait-Timeout |
Connect-Wait-Timeout=30 |
Specifies the number of seconds an Indexer should wait when attempting to connect to replication peers during startup. |
Disable-Server |
Disable-Server=true |
Disable the indexer replication server, it will only act as a client. This is important when using offline replication. |
Disable-Compression |
Disable-Compression=true |
Disable compression on the storage for the replicated data. |
Enable-Transparent-Compression |
Enable-Transparent-Compression=true |
Enable transparent compression on using the host filesystem for replicated data. |
Enable-Transport-Compression |
Enable-Transparent-Compression=true |
Enable transport compression when transmitting data to replication peer. Defaults to |
Delete-Delay |
Delete-Delay=7d |
Set the time required to delete a shard, regardless of storage constraints. Default is “forever”. |
Storage-Reserve |
Storage-Reserve=10 |
Set the percentage of free disk space to keep. Default is 0. |
Disabling Replication Per Well#
The replication engine will replicate all data across all wells by default, however it may be desired to control which datasets are replicated due to costs, priorities, or just when testing Gravwell. Some users find it useful to have a “test” well where data can be ingested and aged out quickly and replicating that test data may not make much sense. Replication can be disabled on a per-well basis by adding the configuration stanza Disable-Replication=true inside the well configuration block. When replication is disabled, the engine will not communicate the wells existence or push any data to replication peers; tags however are always replicated, even if they are assigned to a well with replication disabled.
An example configuration snippet where replication is enabled on an indexer but a specific well is excluded is as follows:
[Replication]
Peer=172.16.2.101
Storage-Location=/opt/gravwell/replication_storage
Connect-Wait-Timeout=60
[Default-Well]
Location=/opt/gravwell/storage/default/
Hot-Duration=365d
Delete-Cold-Data=true
[Storage-Well "testing"]
Location=/opt/gravwell/storage/default/
Tags="testing-*"
Hot-Duration=2d
Delete-Cold-Data=true
Disable-Replication=true
Attention
The default well is not subject to the Disable-Replication configuration parameter and is always replicated. Do not attempt to disable replication on the default well.
Replication Engine Behavior#
The replication engine is a best effort asynchronous replication and restoration system designed to minimize impact on ingest and search. The replication system attempts a best-effort data distribution but focuses on timely assignment and distribution. This means that shards are assigned in a distributed first-come, first-serve order with some guidance based on previous distribution. The system does not attempt a perfectly uniform data distribution and replication peers with higher throughput (either bandwidth, storage, or CPU) may take on a greater replication load than peers with less. When designing a Gravwell cluster topology intended to support data replication, we recommend over-provisioning the replication storage by 10-15% to allow for unexpected bursts or data distribution that is not perfectly uniform.
The replication engine ensures backup of two core pieces of data: tags and the actual entries. The mapping of printable tag names to storage IDs is maintained independently by each indexer and are critical for effective searching. Because the tag to name maps are relatively small, every indexer replicates its entire map to every other replication peer. Data on the other hand is only ever replicated once.
Replication is designed to coordinate with data ageout, migration, and well isolation. When an indexer ages out data to a cold storage pool or deletes it entirely, the data regions are marked as either cold or deleted on remote storage peers. The remote storage peers use deletion, cold storage, and shard age when determining which data to keep and/or restore on a node failure. If data has been marked as deleted by an indexer, the data will not be restored should the indexer fail and recover via replication. Data that has previously been marked as cold will be put directly back into the cold storage pool during restoration. Indexers should restore themselves to the exact same state they were in pre-failure when recovering using replication.
The replication engine takes great care to try and distribute storage load evenly across all available peers; this means that as an indexer is distributing data to replication peers it will often pause for a few seconds to query remote systems about storage usage and shard distribution. These pauses allow all the replication peers to accept shard assignments from other peers as well as generate an accurate picture of replication behavior across a cluster. From a practical standpoint, if replication is engaged for the first time after ingesting significant historical data, the replication system may appear to burst data to peers with high traffic volumes followed by relative calm. This bursty behavior is due to the periods where the system is sampling multiple remote peers. However, if an indexer has a single replication peer, it does not need to perform sampling of remote loads or worry about distributing shards across multiple peers; this simplified replication topology means that the engine can attempt to bring replicated data up to speed as fast as it can, which means the indexers may fully saturate network links transferring very large volumes of data.
Attention
The replication engines first priority is getting data to as safe a state as possible. If an indexer has access to a 40GbE connection and the disks to back it up, it will use that 40GbE of bandwidth.
Replication Storage Management#
By default, replication storage is unbounded — the replication engine will retain all replicated shards indefinitely and never delete them, regardless of how much disk space they consume. Three configuration parameters govern how storage is managed on a replication peer: Max-Replicated-Data-GB, Storage-Reserve, and Delete-Delay.
Max-Replicated-Data-GB sets a hard ceiling on the total amount of disk space the replication system may use. The engine will not delete any replicated shards until this limit has been reached. Once the limit is hit, the engine begins pruning shards according to a priority order: shards that have been deleted on the primary indexer are removed first, followed by the oldest remaining shards.
Storage-Reserve sets a percentage of total disk capacity that must remain free at all times. Like Max-Replicated-Data-GB, it triggers pruning following the same order (first shards marked as deleted, then oldest shards) when free space drops below the specified threshold. Both Max-Replicated-Data-GB and Storage-Reserve can be set simultaneously; the engine will begin pruning as soon as either threshold is crossed.
Delete-Delay controls how the replication peer handles shards that have been deleted on the remote peer. When a remote indexer ages out or explicitly deletes a shard, the replication peer receives a notification and marks that shard as deleted in its local state. Without Delete-Delay, those deleted-status shards are kept indefinitely in replication storage and are only removed when a storage threshold (Max-Replicated-Data-GB or Storage-Reserve) forces the engine to reclaim space. Setting Delete-Delay to a duration (e.g. 7d) causes the engine to hard-delete those shards after the specified time has elapsed regardless of other storage management configurations. Delete-Delay does not require any other storage control to be set to delete data and will not prevent other storage controls from deleting data when thresholds are met.
The following table describes the behavior for a given shard under each combination of settings:
Max-Replicated-Data-GB |
Storage-Reserve |
Delete-Delay |
Result |
|---|---|---|---|
Replication storage grows without bound. No shards are ever deleted. Disk space will eventually be exhausted. |
|||
✅ |
Storage is capped at the configured limit. No deletions occur until the cap is reached, at which point deleted-status shards are pruned first, then oldest shards. Shards deleted on the primary indexer accumulate until storage pressure forces removal. |
||
✅ |
The engine maintains the configured percentage of free disk space. Pruning follows the same order: deleted first and then oldest priority. Shards deleted on the primary indexer accumulate until disk pressure forces removal. |
||
✅ |
✅ |
Both the storage cap and the free-space floor are enforced. Pruning begins as soon as either threshold is crossed. Shards deleted on the primary indexer are held indefinitely until one of the thresholds triggers cleanup. |
|
✅ |
No storage cap or disk reserve is enforced. However, shards that the remote indexer has deleted are hard-deleted from replication storage once the |
||
✅ |
✅ |
Storage is capped. Shards deleted on the primary indexer are proactively hard-deleted after the delay period, keeping the replication store lean. If the cap is still reached, oldest shards are pruned next. |
|
✅ |
✅ |
Free-space reserve is maintained. Shards deleted on the primary indexer are hard-deleted after the delay period. If disk pressure builds from other shards, the engine prunes oldest shards to maintain the reserve. |
|
✅ |
✅ |
✅ |
Fully managed configuration. The storage cap and free-space reserve are both enforced. Shards deleted on the primary indexer are cleaned up promptly after |
Best Practices#
Designing and deploying a high availability Gravwell cluster can be simple as long as a few basic best practices are followed. The following list calls out some guidelines you should follow when deploying and recovering a Gravwell cluster instance.
Indexer-UUIDrepresents an indexer’s global identity. The identity must be maintained for the lifetime of the node and appropriately restored after a failure. If a failed indexer comes up with a different UUID than it previously used, it is interpreted as a wholly new member in the replication cluster and its previous data will not be restored. We recommend noting down the indexer UUIDs somewhere safe in case an indexer suffers catastrophic failure.Changing well configurations can impact replication states. Adding additional wells or deleting wells is perfectly acceptable but changing the well configurations after a failure but before restoration will prevent the replication engine from appropriately restoring data.
If an indexer fails, it is critically important that it be allowed to establish connections with replication peers and perform a first-level tag synchronization prior to ingesting new data. It can be a good idea to set the
Connect-Wait-Timeoutconfig parameter to zero, ensuring the failed indexer will not start until it has established replication connections and performed a tag restoration.Replication storage locations should be reserved exclusively for a single replication system. For example, using the same network attached storage location for multiple indexers’
Storage-Locationwill cause replication failures and data corruption.Match the compression scheme for replicated and primary data. If you are using host based transparent compression on the indexers, it is best to mimic that behavior on the replication stores. If compression schemes match between indexers and replication peers, the restoration process is dramatically faster.
Set
Enable-Transport-Compression=falsewhen replication peers are on a local collision domain. The transport compression is enabled by default but only consumes CPU when operating over local connections where bandwidth is not a concern.
Delayed deletion with Data Ageout#
Replication often serves as the last line of protection against lost data from peers. To further prevent accidental data loss, the replication engine will, by default, only “lazily” delete shards when ageout is enabled. For example, if Node A replicates data to Node B, and Node A ages out a shard, deleting it from hot or cold, Node B will not immediately delete that shard from replication. Instead, it will make the shard unavailable for search, but leave it intact in replication storage. If and when the replication engine needs to delete old shards due to a storage constraint, it will delete these shards first.
This behavior can be changed by setting the Delete-Delay parameter in the replication configuration. For example:
[Replication]
Disable-Server=true
Peer=10.0.01
Storage-Location=/opt/gravwell/replication_storage
Delete-Delay=7d
In the above example, deleted shards will only be retained in the manner above for 7 days. After that time, the shards will be deleted regardless of storage constraints.
Troubleshooting#
Below are potential problems and solutions when debugging a replication problem.
After a failure, an indexer did not restore its data#
Ensure that the indexer maintained its original Indexer-UUID value when coming back online. If the UUID changed, put it back to the original value and ensure the indexer has adequate time to restore all data. Restoration after changing the Indexer-UUID may require significantly more time as the replication system merges the two disparate data stores.
Data is not showing up in the replication Storage-Location#
Ensure that all replication peers have a common Control-Auth (or Replication-Secret-Override) value. If peers cannot authenticate with each other they will not exchange data.
Ensure that X509 certificates are signed by a valid Certificate Authority (CA) that is respected by the keystore on the host systems. If the certificate stores are not valid, either install the public keys into the host machines certificate store, or disable TLS validation via the Insecure-Skip-TLS-Verify option.
Attention
Disabling TLS verification via Insecure-Skip-TLS-Verify opens up replication to man-in-the-middle attacks. An attacker could modify data in flight, potentially corrupting logs or hiding activity in replicated data.
Check firewall rules and/or routing ACLs to ensure that indexers are allowed to communicate with one another on the specified port.
After a failure an indexer is refusing to start due to a failed tag merge#
If an indexer starts ingesting after a failure prior to restoring its tag mapping, it is possible to enter a state where the tag maps on replication nodes cannot be merged. If you encounter an unmergeable tag error, contact support@gravwell.io for assistance in manually restoring the failed node.
After a failure an indexer did not restore all its data#
Replication peers may not have been able to keep up with an indexer due to poor storage performance, poor network performance, or storage failures on the replication node. Ensure that replication peers have adequate bandwidth and storage capacity to keep up with ingestion. If a storage node is ingesting at hundreds of megabytes per second, the replication peers must be able to compute, transfer, and store the data at the same rate.
Also ensure that there was adequate storage on replication peers. If a storage node is configured to keep 10TB of cold data and 1TB of hot data, replication peers should be capable of storing at least 11TB of data. If a replication node was overloaded or misconfigured it may have been removing old data.
Ensure that the system times on replication nodes and indexers are consistent. Both systems use the wall-clock time to determine eligibility of data for removal. If an indexer has an incorrect system time, its data my be prioritized for deletion in the event a replication peer runs out of storage.