
Flows#
Flows provide a no-code method for developing advanced automations in Gravwell. By wiring together nodes in a drag-and-drop user interface, you can:
Run queries
Generate PDF reports
Send emails
Fire off Slack and MS Teams messages
Re-ingest alerts
and more!
This document will describe what makes a flow, the flow editor, and how to debug & deploy your own flows.
Attention
An automation (Flow, Scheduled Search, or Script) runs as the user who owns the automation, except when triggered by an alert.
Granting write access to an automation has important implications. When you grant a group write access to a Flow or Scheduled Search, you are granting them the ability to modify and execute it as your user. Consider using a machine user with the least privileges necessary as the owner of shared automations.
When a flow is run in response to an alert, it runs as the owner of the alert. This also has implications: the alert owner is executing code defined by the flow owner. Don’t use flows owned by untrusted users as consumers on your alerts.
Basic flow concepts#
Flows are automations, meaning they are normally executed on a user-specified schedule by the search agent. You can also run them manually through the user interface. The basic process of flow development is:
Create a new flow
Instantiate nodes in the flow and connect them together
Configure nodes
Test the flow with debug runs
Deploy the flow by setting a schedule & enabling scheduled execution
Nodes#
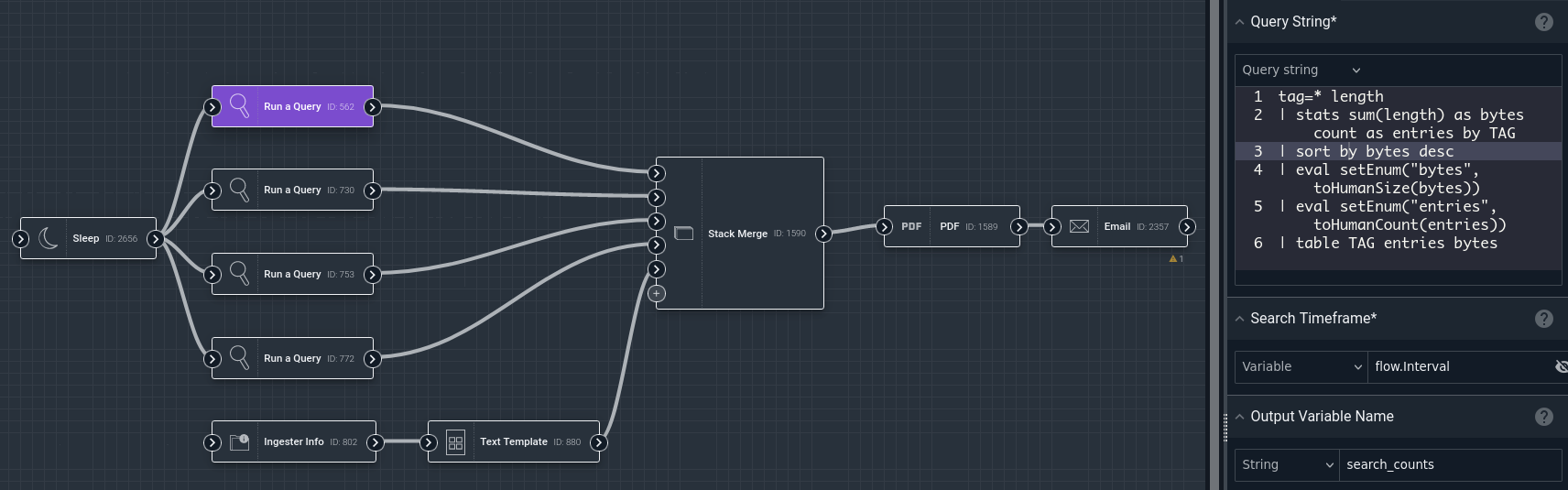
A flow is a collection of nodes, linked together to define an order of execution. Each node does a single task, such as running a query or sending an email. In the example below, the leftmost node runs a Gravwell query, then the middle node formats the results of that query into a PDF document, and finally the rightmost node sends that PDF document as an email attachment.

All nodes have a single output socket. Most have only a single input socket, but some nodes which merge payloads (see below) have multiple input sockets.
One node’s output socket may be connected to the inputs of multiple other nodes, but each input socket can only take one connection.
Payloads#
Payloads are collections of data passed from node to node, representing the state of execution. For instance, the “Run a Query” node will insert an item named “search” into the payload, containing things like the query results and metadata about the search. The PDF node can read that “search” item, format it into a nice PDF document, and insert the PDF file back into the payload with a name like “gravwell.pdf”. Then the Email node can be configured to attach “gravwell.pdf” to the outgoing email.
The node receives an incoming payload through its input socket, then passes its outgoing payload via the output socket. In most cases, the outgoing payload will be a modified version of the incoming payload.
The first node to execute will always receive a payload pre-loaded with the following items:
flow(structure containing information about the flow & the current execution)Debug: set to true if the flow was run manually in the flow editor.Description: the Description field of the flow definition.Executed: the time at which the flow started execution.Interval: the number of nanoseconds between executions according to the flow schedule.Labels: any labels attached to the flow.LastRun: the time at which the flow was last executed.MaxRunDuration: how long the flow can run, in nanoseconds, before being terminated.Name: the name of the flow.NetworkAllowed: if true, the flow is allowed to use network functions such as the HTTP node.Scheduled: the time at which the flow was scheduled to run; if run manually, the time at which the request was sent.UID: the user ID of the flow’s owner.User: the username of the flow’s owner.
event(structure containing information about the event which triggered an Alert to launch the flow)Contents: (structure containing enumerated values from the triggering event)Metadata: (structure containing information about the alert which was triggered)AlertActivation: a UUID referring to a specific activation of the given alert.AlertID: the unique ID of the alert that was triggered.AlertLabels: any labels attached to the alert.AlertName: the name of the triggered alert.Consumers: an array containing information about all consumers of the alert.ID: the unique ID of the consumer.Labels: any labels applied to the consumer.Name: the name of the consumer.Type: the type of the consumer (currently, always “flow”)
Created: the time at which the alert was created.Dispatcher: information about the automation which triggered the alert.EventCount: the number of events created by the specific run of the dispatcher.EventsElided: set to true if there were more events than allowed by the alert’s Max Events option.ID: the unique ID of the triggering dispatcher.Labels: any labels applied to the dispatcher.Name: the name of the dispatcher.SearchID: the ID of the particular search which generated the events.Type: the type of the dispatcher (current, always “scheduledsearch”)
EventIndex: dispatchers may emit multiple events, each processed by a single run of the consumer; this field represents the 0-indexed event number which is being processed by the current flow execution.TargetTag: the tag into which events for this alert will be ingested.UID: the user ID of the alert’s owner.UserMetadata: user-specified additional fields defined on the alert.Username: the username of the alert’s owner.
Type: a constant string, “event” (not particularly useful in flows)
The event fields can be particularly useful when generating messages about an event, for example the Text Template node could be used to generate a human-friendly message formatting event.Metadata.Dispatcher.Name and event.Metadata.AlertName, plus the values in event.Contents. See the Alerts documentation for examples.
Execution order#
Nodes are always executed one at a time. A node can be executed if all nodes upstream of it (its dependencies) have executed. If multiple nodes are ready to execute, one will be chosen at random. In the example below, both the “Run a Query” node and the “HTTP” node are candidates to run first. After the Query node finishes, the If node can execute; when it is done, the Slack Message node may run. We say that the If node is downstream of the Query node, and the Slack node is downstream of both the If and Query nodes.
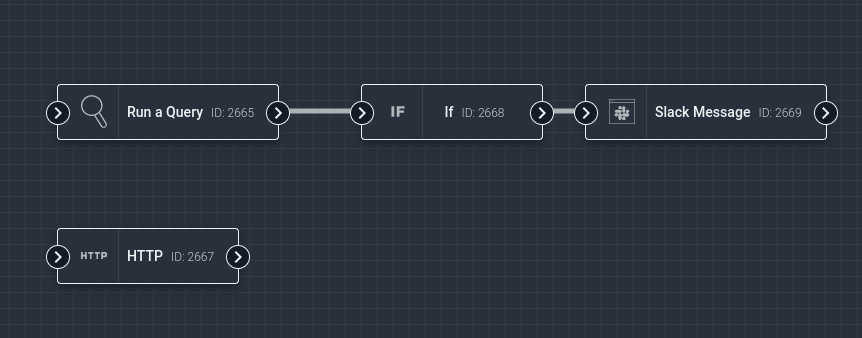
Note that some nodes may block execution of downstream nodes. The If node is configured with a boolean logic expression; if that expression evaluates to false, none of the If node’s downstream nodes are executed. Nodes which can block downstream execution will always have a note to that effect in the online documentation.
If a node returns an error during execution, downstream nodes will not execute, but any other nodes which are not downstream will execute before the flow exits.
Flow editor#
Flows are created using the flow editor. Please refer to the flow editor documentation for a detailed description of the editor, instructions on how to use it, and information about debugging & scheduling flows.
Common Flow Patterns#
Because flows are quite flexible, it can be a bit daunting trying to figure out how to tackle a given task. We have collected some common flow patterns to help with this.
Node list#
Attach: Attach to an existing Gravwell query.
Background/Save Search: Save or background a Gravwell query.
Email: send email.
Flow Storage Read: read items from a persistent storage.
Flow Storage Write: write items into a persistent storage.
Gravwell Notification: set Gravwell notifications.
Go Scripting: execute Go code in the flow.
Google Chat: send a Google Chat message.
HTML Format: format variables as HTML.
HTTP: do HTTP requests.
If: perform logical operations.
Indexer Info: get information about Gravwell indexers.
Ingest: ingest data into Gravwell.
Ingester Info: get information about Gravwell ingesters.
JavaScript: run JavaScript code.
JSON Encode/Decode: encode and decode JSON.
Logbot: analyze and explain log data using AI.
Mattermost Message: send a Mattermost message.
Nest Merge: join multiple input payloads into one.
PagerDuty: Create incidents in PagerDuty.
PDF: create PDF documents.
Query Log Ingest: convert search results to alert entries & ingest.
Read Macros: read Gravwell macros.
Read Resources: read Gravwell resources.
Rename: rename variables in the payload.
Run a Query: run a Gravwell query.
Run Query - Advanced: run a Gravwell query with more flexible options.
Set Variables: inject variables into the payload.
Slack File: upload a file to a Slack channel.
Slack Message: send a message to a Slack channel.
Sleep: pause flow execution for a given period of time.
Splunk Query: run a Splunk query.
SQL Query: run SQL queries against external databases.
Stack Merge: join multiple input payloads into one.
Teams Message: send a Microsoft Teams message.
Text Template: format text.
Throttle: limit execution frequency of certain nodes within a flow.
Update Resources: create or update Gravwell resources.
The following nodes tend to be needed only in particular advanced cases:
Get Table Results: get results from a search using the table renderer.
Get Text Results: get results from a search using the text renderer.